A Brief History of the Spoofax Language Workbench
In November 2020 the most influential paper award for OOPSLA 2020 was awarded to the paper
The Spoofax language workbench: rules for declarative specification of languages and IDEs.
by Lennart C. L. Kats and Eelco Visser.
OOPSLA 2010. [PDF]
This was the second award for the paper! It had already been awarded the best student paper (for a paper with a student as primary author) at OOPSLA 2010, which was effectively the best paper award, since there was no such award that year.
In this post I reconstruct the journey to that paper and the first version of the Spoofax language workbench, and how Spoofax and the research has evolved since 2010. This will show that the Spoofax system packs a great deal of interesting additional research and engineering produced before, during, and after the paper and the creation of its first release. I also hope to convey that programming systems research is a matter of persistence. While conceptual insights are important, their realization in working systems is just as important to demonstrate their viability, enable further impact, and generate inspiration for new research.
Note that while this post is (too) long, it is only a part of the full story. For details see the linked publications and their discussions of related work. See my publication list for strands of research not represented here.
This post is a draft. If you have feedback, please let me know.
Software Language Engineering
The Spoofax language workbench comes out of the language engineering research program that has its roots in the BNF (Backus-Naur Form) notation and the YACC (Yet Another Compiler Compiler) parser generator. The webpage of the SLE 2021 conference defines software language engineering as
the discipline of engineering languages and their tools required for the creation of software. It abstracts from the differences between programming languages, modelling languages, and other software languages, and emphasizes the engineering facet of the creation of such languages, that is, the establishment of the scientific methods and practices that enable the best results.
Language engineering is concerned with the creation of all sorts of tools for processing languages including parsers, intepreters, compilers, and editors. That is, programming environments in the broadest sense of the word. Rather than engineering such tools for specific languages, a goal of the language engineering research program is to differentiate between language specific and language independent aspects of language implementations and make the generic aspects reusable between language implementations.
As a concrete example, a parser generator only requires the specification of the grammar of a language (the language specific rules) to automatically generate the implementation of a parser implementation for the language, thus reusing the language independent knowledge about parsing.
Thus, a language parametric tool is parameterized with language specific rules and uses language independent knowledge to produce an implementation. At a high level we can see the language engineering research program to extend the scope of such language parametric tools by developing better abstractions for language definition and extending the language parametric approach to more aspects of language engineering.
Before Spoofax
The story leading to Spoofax begins long before ‘software language engineering’ was coined and is a tale of four cities.
Amsterdam: SDF2
I did my PhD in the group of Paul Klint at CWI/UvA in Amsterdam (1993-1997). At the time I started my PhD, a first version of the ASF+SDF MetaEnvironment had been developed in Centaur using LeLisp. It featured declarative syntax definition in SDF and program transformation by means of term rewriting defined with rewrite rules defined in the concrete syntax of the language under development. Syntax definition of arbitrary context-free grammars was supported by the Generalized LR parsing algorithm developed by Jan Rekers. The engine underlying the MetaEnvironment supported live, incremental, and modular building of a programming environment for a language. Effectively, this was a language workbench although we didn’t call it that at the time. However, the MetaEnvironment lacked most advanced editor services of modern IDEs and its graphical user interface was custom developed.
During my PhD I developed SDF2, a redesign of the SDF syntax definition formalism. Inspired by the work of Salomom and Cormack, the SDF2 defined lexical syntax using the same context-free grammar productions as the context-free syntax. To support that integration I developed the Scannerless GLR algorithm for parsing character level grammars. After my PhD, Jeroen Scheerder and Jurgen Vinju continued the work on SDF2 and SGLR. The motivation for scannerless parsing was mostly internal, i.e. as a more principled approach to specify syntax and to improve the interface between a scanner and a parser in the context of generalized parsing. Only later (see Utrecht), did we realize that scannerless parsing is ideally suited to deal with language composition.
Portland: Stratego
During my one-year postdoc (1997-1998) at the Oregon Graduate Institute with Andrew Tolmach, I developed the Stratego transformation language. While I liked term rewriting in ASF+SDF, its fixed innermost rewriting strategy forced programming in a style that coincided with first-order functional programming with a lot of overhead for the definition of traversals.
At the end of my PhD in Amsterdam, we had visited the INRIA research group of the Kirchners in Nancy.
They were developing the ELAN, language, which featured a strategy language for directing the application of rewrite rules.
Inspired by that language, Bas Luttik and I, explored the definition of generic traversal strategies.
Using modal all, one, and some operators to define one-level traversal, one can define a wide range of traversals.
In Portland I worked out this idea in the Stratego transformation language, which is based on rewriting, but makes the strategies that are used to apply rewrite rules programmable. I developed the first interpreter in MetaML, which was developed locally at OGI by Tim Sheard and Walid Taha, with the idea to use it for staging the interpreter. By the time I presented the ICFP’98 paper about Stratego in Maryland, I had used the interpreter to bootstrap a compiler written in Stratego, which generated C code.
The ideas of rewriting strategies and generic traversal were adopted in internal DSLs in several languages including Scrap Your Boilerplate in Haskell, raddsl in Python, RubyWrite in Ruby, and ELEVATE in Scala.
Utrecht: Stratego/XT
After my postdoc I landed an assistant professor position at Utrecht University in the Software Technology group of Doaitse Swierstra (1998-2006). In Utrecht I further developed the Stratego language and combined it with the SDF2 implementation from CWI in the Stratego/XT toolset for program transformation together with a growing group of master students, PhD students, and postdocs, including Eelco Dolstra, Martin Bravenboer, and Merijn de Jonge.
The toolset included a growing set of libraries and utilities for language engineering, including a compiler and interpreter for Stratego, a parser generator for SDF2, the SGLR parser, a Box intermediate language for pretty-printing, an interpreter of pretty-print tables, the XTC library for transformation tool composition, and instantiations for several languages. And we developed extensive documentation for Stratego/XT.
Stratego/XT ran on the C/Linux platform. Automatically building and releasing (binary) distributions was a non-trivial undertaking and led to a side track to investigate improving software build and deployment practices. Eelco Dolstra, as a PhD student, developed Nix, a purely functional software deployment system and, as a postdoc, extended that to the NixOS linux distribution.
On the front of program transformation, there were two big research themes.
To express context-sensitive transformations, we extended Stratego with dynamic rewrite rules. For example, for function inlining, when encountering a function definition one defines a dynamic rewrite rule to inline calls of the function, and when encountering a function calls, the collection of all inlining rules is applied. In order to account for name binding, the introduction of dynamic rules could be scoped. This allowed mirroring the lexical binding patterns of programming languages.
The other big theme of this era was language composition, which was triggered by a talk by Tim Sheard on the accomplishments and research challenges in meta-programming in the SAGE 2001 workshop. One of the challenges he mentioned was the (syntactic) composition of languages. To demonstrate that this was very well supported by SDF2/SGLR, I wrote a paper for (the first) GPCE’02 on meta-programming with concrete object syntax in which the patterns of Stratego rules can be written in the concrete syntax of the language under transformation by composing the grammar of the meta-language and the grammar of the object language. Martin Bravenboer picked up the theme and starting with concrete syntax for objects, the approach was extended to grammar composition for a range of applications, including the prevention of injection attacks and the syntax of AspectJ, which Martin integregrated in a PhD thesis on exercises in free syntax. (We still need to integrate the work on parse table composition, i.e. separate compilation of grammars.)
Indeed, after a succesful master thesis project on mixing source and bytecode, Lennart Kats was hired as a PhD student, with the goal to improve the semantics of language composition.
Delft: WebDSL and Mobl
In 2006 I became an associate professor at Delft University of Technology (TU Delft for short) in the Software Engineering Research Group (SERG) of Arie van Deursen.
A frustration with the work on Stratego/XT was that all case studies involved toy languages. While I tried to do transformations on Haskell, reconstructing a Haskell front-end was a daunting task. Thus, I decided to target the development of domain-specific languages. In the academic year 2006-2007 I had no teaching duties and decided to use the time to design and implement a web programming language using Stratego/XT. The project name was, prosaically, WebDSL. WebDSL is really a collection of DSLs for different aspects of web programming, integrated into a single language. The aspects covered by WebDSL include data modeling, user interface templates, access control, and search. WebDSL took off in Delft with many students, including Danny Groenewegen and Zef Hemel, contributing to its development. Elmer van Chastelet was one of the master students who joined the project later and contributed the search sub-DSL. The language has led to a several web applications used in production, including researchr (2009), WebLab (2011), and conf.researchr (2014).
WebDSL was used as a case study in language design, an examplar of static consistency checking across domains, and code generation by model transformation. Zef Hemel later developed the mobl language, adapting the WebDSL ideas to client-side web programming, especially directed at mobile phones. (The first iphone was introduced in 2007.)
The Rise of IDEs
Starting in the early 2000s, Integrated Development Environments (IDEs) such as IntelliJ IDEA and Eclipse were becoming mature interactive programming environments assisting programmers with a range of features such as syntax highlighting, navigation, and code completion.
An IDE for Stratego/XT
Stratego/XT was a command-line framework (including a REPL). We edited programs in emacs without any language-specific editor support. Having witnessed the trouble of developing a graphical user interface for the MetaEnvironment, I had stayed away from them in the Stratego/XT project. But that was no longer viable.
Many students in the lab were enthusiastic about Eclipse and the Java programming language, including Karl Trygve Kalleberg, a PhD student at the University of Bergen in the group of Magne Haveraaen who came to spend a year (2004-2005) at Utrecht University. He decided to develop Eclipse plugins for SDF2 and Stratego in a project on the side of his PhD work. Since the implementations of SDF2 and Stratego were bootstrapped, that required porting the SGLR parser and the Stratego compiler and intepreter to Java.
Karl proposed Spoofax as name for the Eclipse plugin. I remember he told me about the project and the name, on a snow filled Uithof campus, just before returning to Bergen. He explained the motivation for the name as deriving from a domain name engineering exercise, i.e. finding a name with zero hits in a Google search and with a free domain name: spoofax.org. I didn’t particularly like the name, but didn’t think too much of it. It was just for an editor, after all. And it would be easy to find.
The experiment demonstrated that the custom production of an Eclipse plugin for a language was non-trivial and involved a lot of boilerlate code. It was not appealing to construct one for each DSL defined with Stratego/XT.
Language Workbenches
In 2004, Martin Fowler coined the term language workbench, for tools that support the creation of interactive programming environments for domain-specific languages. The example in Fowler’s post was the MPS tool from JetBrains, which was based on projectional editing (also known as structure editing) instead of the textual editing supported by mainstream IDEs. He describes the three main parts of defining a DSL as comprising a schema, an editor, and a generator. The schema corresponds to the abstract syntax of a language, the (projectional) editor replaces the parser, and the generator corresponds to the compiler. Beyond its specific approach to projectional editing, Fowler’s post emphasized the importance of interactive programming environments for programming languages and the idea to be able to create those easily as part of the language design process for DSLs.
Eclipse IMP
While attending the program comittee meeting of OOPSLA 2007 at IBM in Yorktown Heights in May 2007, I met Bob Fuhrer from IBM Research who told me that they would release Eclipse IMP later that year (as an open source framework!). The IDE Meta-tooling Platform (IMP) should make it easier to develop Eclipse plugins.
It seemed like a good opportunity for Lennart Kats, before he would start on the real work of semantic language composition, to explore the possibilities of this new platform. This resulted in SDF2IMP, a generator that produced an Eclipse plugin with a syntax aware editor based on an SDF2 definition for a language. SDF2IMP was a static generator. That is, given an SDF2 definition, it produced a Java implementation of an Eclipse plugin. After compiling and starting a new Eclipse instance, one could use the resulting editor. A cumbersome workflow.
The Spoofax Language Workbench
Combining SDF2 and Stratego with IMP, Lennart developed Spoofax/IMP, a language workbench for the development of new (domain-specific) programming languages, and we wrote the comprehensive OOPSLA’10 paper. On rereading the paper, I can only agree with the award committees of OOPSLA 2010 and the MIP committee for OOPSLA 2020. (Read: I am not embarrassed by the awards.) The paper is very well written, motivates the problem it solves, positions the solution in the context of related work, and comprehensively describes the design of a complex system with many components. Doing justice to the paper would amount to copying it. Thus, I would like to encourage the reader to read the paper itself. But I’ll give a high-level summary of the contributions of the paper.
Editor Services
IDEs extend the standard compiler/interpreter of a programming language with a range of editor services, which can be divided into services related to syntax, presentation, editing, and semantics:
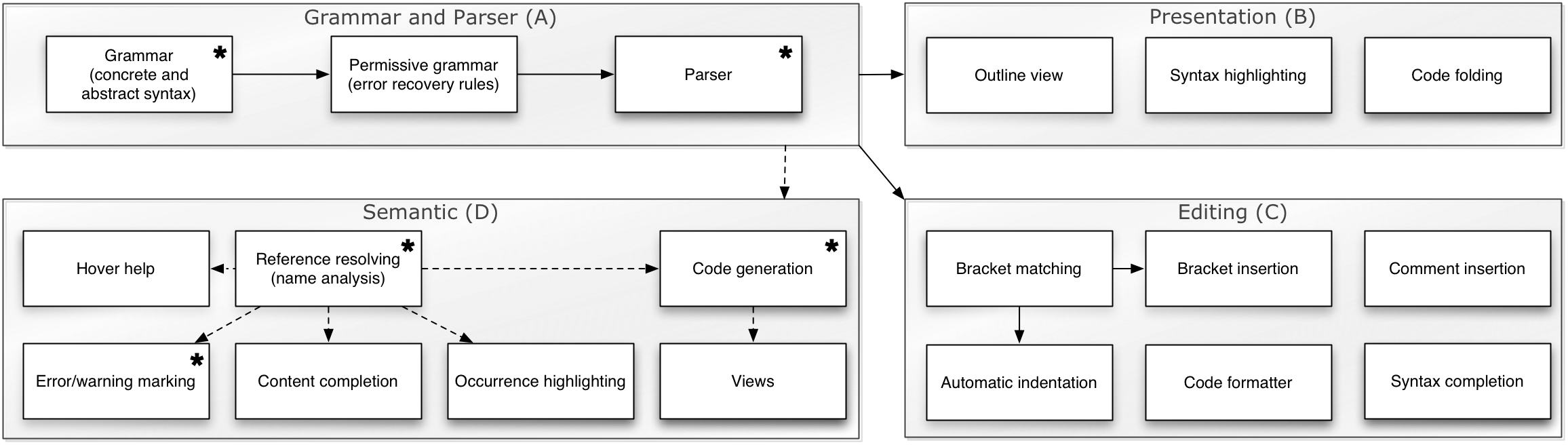
In addition to categorizing the services, the figure depicts the “relations between IDE components. Dependency flow is indicated with arrows; generative dependencies are indicated with a solid line. Components with an asterisk are generally also part of traditional batch compiler implementations.”
In traditional language design, the development of an IDE is seen as a separate concern from developing the core compiler/interpreter. Instead, the OOPSLA’10 paper “shows how a single semantic description based on rewrite rules can be used for both compilation and interactive editor services such as error markers, reference resolving, and content completion.” In Spoofax, a language project defines syntax using SDF2, semantic definitions using Stratego, and editor services are described in the ESV configuration language. If services can be generated, they are clearly marked as such and should not be edited, in order to avoid maintenance problems in the future, a common pitfall in generative programming.
Origin Tracking
An important improvement of an IDE over a command-line compiler and simple editor is that feedback from the analysis phase of compilation is displayed inline in the editor, and that a navigational service such as reference resolution jumps to the declaration corresponding to a reference (possibly in another file). Implementing that services requires keep track of the locations of nodes in the abstract syntax tree in the underlying text. Spoofax enables such services by automatically recording the source locations in the abstract syntax tree and relying on origin tracking to propagate source locations through the transformation process. Thus, a language implementer does not need to implement additional data structures for this purpose.
Agile Language Development
A key feature of Spoofax is the dynamic loading of language implementations. Instead of starting a new instance of Eclipse to test the plugin built for a language, it is loaded into the same Eclipse instance that is used for development of the language. The following screenshot from a Spoofax session illustrates the workflow. The two editors on the left define the syntax and static semantics of a language, and the editor on the right is the language-aware editor reflecting those definitions:
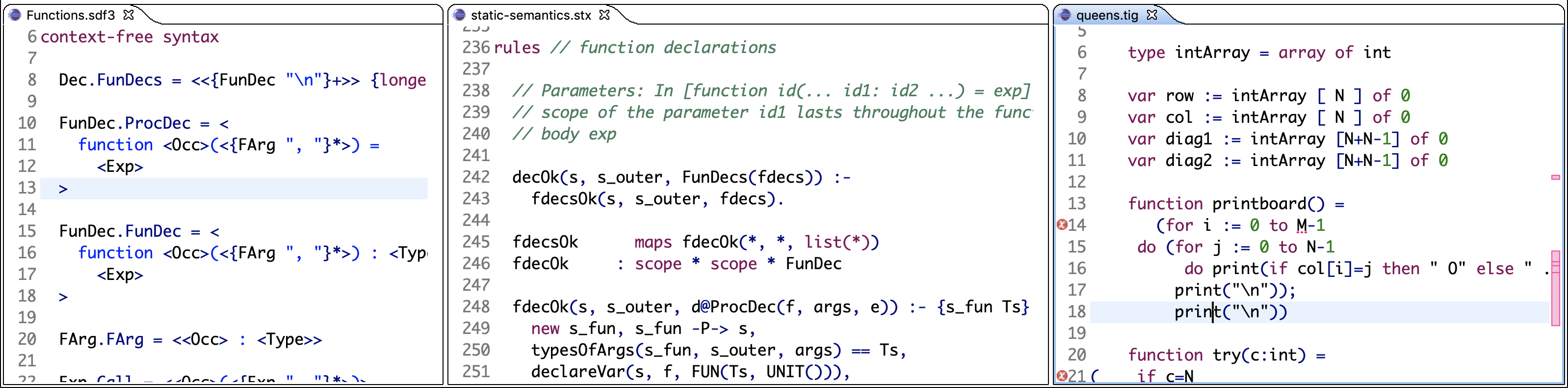
This enables an agile language development process, providing a quick turn-around for language experiments.
Bootstrapped, Declarative Rules
Finally, rather than using general-purpose programming languages, Spoofax uses “rules for declarative specification of languages and IDEs”. The syntax of a language is defined using context-free grammars with extensions, from which a parser and other services are generated. The semantics of a language is defined using the Stratego transformation language, which works directly on abstract syntax terms, and supports origin tracking. Moreover, the Spoofax meta-languages are bootstrapped, that is, developed using Spoofax. That means that all its facilities are available to those meta-languages as well. It is as easy to develop meta-languages as it is to develop DSLs, and any improvements to Spoofax benefit its meta-languages as well.
Parallel Developments
Spoofax can be seen as a project that integrated components produced by earlier research into a new system. However, in addition to integrating existing research, it also produced several new research contributions, which were separately published, and in which Lennart had a heavy hand.
Parse Error Recovery
The early Spoofax editor for SDF2 and Stratego, and the SDF2IMP experiment made clear that IDEs require error recovery to be usable. A program under development is in an erroneous state frequently, and the editor services should work also on such erroneous programs. The SGLR parser for SDF2 did not support error recovery, so we extended the algorithm. The approach consisted of two innovative ideas. First, we expressed parse error recovery by means of permissive grammars, i.e., grammars with additional productions that allow parsing erroneous programs. Following the paradigm of island grammars , we developed water tokens, such that erroneous tokens could be considered as comment. Next, we extended the breadth-first SGLR algorithm with backtracking to selectively explore permissive alternatives after the core grammar productions fail. See the papers at SLE’09 and OOPSLA’09, consolidated in a TOPLAS journal article.
Language Testing
Improving the reliability of language implementations requires language testing. To support the definition of tests for language developed in Spoofax, we developed SPT, a domain-specific language for testing the various aspects of a language definition. For example, the following test defines name resolution for a let binding:

A test consists of a language fragment in the concrete syntax of the language under test and one or more test expectations to express some requirement, which can cover syntax, analysis, and transformation. Such tests are independent of a particular implementation of a language, or indeed of the testing language itself. Thus, SPT could be used to provide a canonical test suite for a language.
Name Binding
Finally, the last project that Lennart was involved in was to make name resolution more declarative. In the Spoofax paper we discuss a Stratego design pattern for defining the static semantics using rules for checking constraints, name analysis, and type analysis that had been developed over the course of several language definitions. However, this remains a rather operational definition.
The NaBL was our first attempt at developing a declarative DSL for the definition of name binding rules. In NaBL, “we identify recurring patterns for name bindings in programming languages and introduce a declarative metalanguage for the specification of name bindings in terms of namespaces, definition sites, use sites, and scopes.” For example, the following rules define the names that fields, method, and variable declarations introduce, and the references of calls and variables to those definitions:

From an NaBL definition, we generated a name analysis algorithm, reference resolution, and code completion.
Early Impact
Industry: Oracle
At the IFIP Working Group 2.11 meeting in Bordeaux in 2011 Hassan Chafi from Oracle Research approached me to discuss the use of Spoofax for the development of their graph analytics DSL Green-Marl, which was developed in C++ and running into maintenance problems. We continued the conversation at SPLASH/OOPSLA’12 in a foodcourt in Portland and then at Oracle in Redwood City. To my pleasant surprise this actually developed into a fruitful collaboration and Oracle contributed funding to the further development through their External Research Office program. For Oracle this resulted in a language implementation that could evolve quickly with demand, making it easier to extend the language and its compiler. Spoofax is currently used for a compiler with several back-ends.
Academia: SugarJ
Sebastian Erdweg, then a PhD student in Marburg with Klaus Ostermann developed SugarJ, an exensible Java in which language extension were defined in SDF2 and Stratego. SugarJ extended Spoofax to provide editors for extended languages.
Education: Compiler Construction
At TU Delft, Guido Wachsmuth developed a compiler construction course. In the course, we teach language definition using declarative meta-languages, which allows students to implement a full fledged compiler for a language of some complexity, together with an IDE within the course of a semester. For a long time, we used MiniJava and Jasmin as project language, but in 2020-2021 we switched to ChocoPy as project language, compiling to RISC-V.
Beyond Spoofax 1
The construction of Spoofax was a considerable effort, and its release coincided with a generation of PhD students graduating and moving on to new challenges. The question was what would be next.
Web IDEs
One direction that seemed interesting, especially to Lennart, was the evolution of IDEs to web-based, online tools. After his PhD (on mobl), Zef Hemel had moved to Cloud9, a company that was developing the ACE editor and a web IDE around it. It would be great if language workbenches would be able to generate plugins for web IDEs, just as they did for desktop IDEs. We did some experiments porting SGLR and Stratego to JavaScript using the Google Webtoolkit. The result was a rather heavyweight and not very fast port of Spoofax editors to the web. It was clear that web IDEs needed a lot more architectural investigation and that running such tools required considerable resources on the server side. The ACE editor ended up in the WebLab learning management system, which we developed for programming education. We described our exploration in a research agenda for Onward’12. At TU Delft, this research was stalled, but Lennart decided this was the future for him, and he joined Cloud9. Cloud9 was eventually acquired by Amazon. Recently, we tentatively picked up this line of work again, and have now several Spoofax meta-languages running in WebLab.
Towards Flexible Pipelines
In parallel, we pursued the evolution of desktop Spoofax. Spoofax/IMP was a great prototype, but some also considered it a pile of hacks. Could we make a more principled language workbench? Principled in the creation of its components, and principled in its architecture.
Regarding its architecture, Spoofax was completely entangled with Eclipse and with IMP. This made Spoofax language definitions unusable outside that setting. Gabriël Konat developed Spoofax Core (aka Spoofax 2), a Java library that makes Spoofax more robust and independent from Eclipse and IMP, so that it can be used from the command-line and from other IDE containers, such as IntelliJ. The current Spoofax release has Spoofax Core as its architecture.
The development of Spoofax Core included an investigation of the bootstrapping process of meta-languages. Defining meta-language in Spoofax itself is advantagous as a way to test the workbench and to enjoy its benefits for language definition, but boostrapping is a delicate process, when language mutually dependent on each other.
One of the observations was that the build process of language projects, generated editors, and the workbench itself was complicated and fragile, involving a multitude of build system. The lack of soundness and completeness in the build process contributed to obscure bugs in the workbench. Redefining the build of language projects in pluto improved this process. The PIE build system and DSL improves on pluto, by not traversing the entire dependency graph, but only performing a bottom-up search, starting with the changed artifacts.
Supported by Oracle, Gabriël currently leads the effort of building Spoofax/PIE (aka Spoofax 3), in which all build steps, from coarse to fine grained, are defined in PIE and can thus be incrementalized. This should lead to more flexible composition of compiler pipelines, sound and complete incrementality, and truly live language development.
Declarative Language Definition
The promise of Spoofax was to derive multiple artifacts from a single language definition. In practice, Spoofax 1 required quite a few additional definitions to realize an IDE. Thus, a major part of the research of my group at TU Delft is to realize that aspiration and create a true Language Designer’s Workbench that supports the derivation of all artifacts of a language implementation from a high-level, declarative language definition, and guarantee safety and completeness properties by construction. This is very much a work in progress.
Syntax Definition
From the day I started my PhD on syntax, it seemed that ‘syntax is a solved problem’. However, parsing seems poorly understood and the mainstream tools for managing the syntactic aspects of programming languages do a poor job. In addition to parse error recovery (discussed above) we (mostly Eduardo Amorim) developed SDF3 including template productions for derivation of pretty-printers, layout constraints for parsing and pretty-printing layout-sensitive syntax, an extension of disambiguation rules to deep priority conflicts, and syntactic completion. A recent overview discusses how SDF3 supports multi-purpose syntax definition.
Data-Flow Analysis
Jeff Smits has developed FlowSpec, a meta-language for the definition of intra-procedural data-flow analyses in terms of control-flow graphs and transfer functions. From such specifications, we generate program analysis tools.
Static Semantics
The reviewers of a follow-up paper on the NaBL name binding language, asked for a proper semantics of the language for a revision of the paper. The attempt to provide that quickly failed, and the special issue version of the paper never materialized. Instead, we embarked on a multi-year project to understand the semantics of name binding. This ended up in the conception of scope graphs as a language independent representation of the binding structure of programs, driving a language parametric name resolution algorithm.
Hendrik van Antwerpen led the effort of designing a meta-language for static semantics based on scope graphs. We combined constraints for the construction and querying of scope graphs with unification constraints to form a constraint language (dubbed NaBL2) for the definition of the static semantics of programming languages. The language was then refined (and renamed to Statix) to account for more advanced type systems and a precise account of scheduling name resolution in order to automatically derive type checkers. Currently, we are improving the performance of these type checkers, extending the coverage of Statix, and exploring other interpretations of Statix specifications, such as code completion and refactorings. Even language composition is back as a research topic.
Dynamic Semantics
Traditionally, language engineering tools are geared towards the front-end of language definitions. With SDF2 and Statix we are really getting closer to the ideal of a language designer’s workbench. For defining the behavior of programmig languages such tools have traditionally defaulted to the definition of code generators using string templates or AST to AST transformations. The theory of programming languages provides various formalisms for defining the run-time behavior, or dynamic semantics, including denotational and operational semantics. However, following what we do for language front-ends, we would like to automatically derive interpreters, compilers, and optimizers from semantics definitions. Dynamic semantics, the final frontier of language engineering!
In Delft, we are attacking this challenge from several angles. We have even attracted Peter Mosses, professor emeritus from Swansea University, to spend his retirement in the Delft PL group to share his long experience on this topic. (He also works on CBS, a component-based language specification framework.)
One line of attack is the design of a meta-language for the definition of operational semantics. DynSem is a DSL in the tradition of MSOS by supporting modularity of operational semantics rules by implicitly passing semantic components. Vlad Vergu experimented with the implementation of DynSem with a meta-interpreter in Graal and its specialization by using scopes-and-frames with promising performance improvements, although there is still quite a distance to directly interpreted code. However, the range of effects supported by DynSem is limited (cumbersome exceptions, no continuations). Thus, we are currently exploring the definition of Dynamix, a successor of DynSem, with increased expressivity.
Another line of research is to ensure type safety of dynamic semantics specifications.
The scopes describe frames approach uses the scope graph model from a Statix specification to provide a standardized representation of memory, making the safety proof systematic.
In order to ensure type safety by construction we are exploring intrinsically-typed definitional interpreters and compilers defined in the dependently-typed programming language Agda. To date, we have extended the approach to interpreters for languages with state and session types, and to bytecode compilers.
This work has not made it yet into the language workbench.
Transformation
Finally, we are starting to work again on transformations. In particular, definitions of transformations that take into account and preserve the name binding and type analysis of the object language. We are exploring this in a project in collaboration with Philips to produce a language parametric tool for programming software restructurings. We’re hiring two PhD Students to work on this project.
Conclusion
I hope this post has made clear that the Spoofax paper earned a most-influential paper award, not just because it is a well-written (and well cited) paper, but also because the Spoofax system packs a great deal of interesting additional research and engineering produced before, during, and after the paper and the creation of its first release. Research in programming systems requires a great deal of persistence. The pointers in this post should provide a starting point for exploring that research.
Many times in my career I have heard colleague researchers (predecessors, students) state that “all that is left to do on this system/topic/approach is engineering (i.e no research challenges are left)”, while in fact many aspects were not well understood, did not work very well, needed further optimization, were not formalized/verified, could be specified more declaratively, could be generalized, etc. That is certainly the case of Spoofax, in particular, and the study of language engineering and declarative language definition, in general; there is plenty of interesting and challenging work to do. Researchers interested in contributing are most welcome. Spoofax is developed in the open, as an open source project. (Drop me a line if you want an invitation for the #spoofax-users channel on our Slack organization.)
Making software that is more reliable, efficient, robust, and secure, requires that we increase our understanding of the methods for creating that software.