Research and Software Projects with Selected Publications
- Expressing Intent
- Programming Environments
- Spoofax
- ASF+SDF
- Syntax
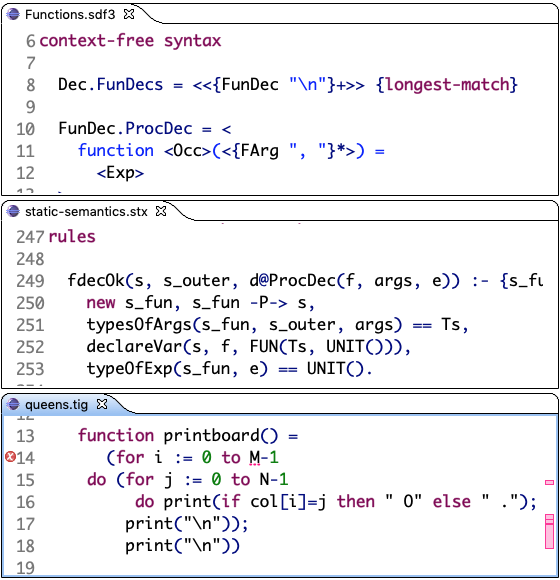
- SDF3
- Disambiguation
- SGLR
- LangComp
- SDF2
- Statics
- Statix
- Scope Graphs
- NaBL
- FlowSpec
- Dynamics
- AutoSound
- DynSem
- Transformation
- Stratego
- Concrete Syntax
- C++
- Stratego/XT
- Testing
- SPT
- Build & Deploy
- PIE
- Nix
- Web Programming
- WebDSL
- IceDust
- mobl
- Web Apps
- WebLab
- conf.researchr
- researchr
Expressing Intent
How to enable software engineers to express intent directly in terms of the concepts of a domain of interest (and get the corresponding implementation for free)? Most of my (group's) research is related, one way or another, to that question, and includes: design of meta-languages for language design (to support the development of new languages), language theory and implementation techniques (such as parsing, name resolution, constraint solving, rewriting), design of domain-specific languages for particular domains (such as web programming, build systems, digital printers), evaluation of these languages in applications (such as WebLab, conf.researchr.org).
All results are available for application, reproduction, and further research through open source software distributions or open web services. Furthermore, we emphasize development of research software to the extent that it is usable in production systems, since that is the only true test for conceptual ideas. This requires engineering work beyond prototypes sufficient to merit publication. But the resulting systems provide fertile ground for future research. For example, the Spoofax language workbench is bootstrapped, i.e. its meta-language are implemented with Spoofax. WebDSL is a production language built with Spoofax. The WebLab learning management system and the conf.researchr.org conference management system are built with WebDSL.
This page lists (many of) the projects my group works on, or has worked on, along with selected publications. The projects are organized per research topic. (And not in reverse chronological order; some more recent projects occur further down on the list.)
My current focus is on the following projects: Spoofax | SDF3 | Disambiguation | SGLR | Statix | AutoSound | PIE. Some new projects are in start-up phase and are not listed here yet.
-
In this essay, I argue that linguistic abstraction should be used systematically as a tool to capture our emerging understanding of domains of computation. Moreover, to enable that systematic application, we need to capture our understanding of the domain of linguistic abstraction itself in higher-level meta languages. The argument is illustrated with examples from the SDF, Stratego, Spoofax, and WebDSL projects in which I explore these ideas.
Programming Environments
Goal: To generate language-specific interactive programming environments --- with editor services such as error recovery, code completion, and refactoring --- from declarative language definitions.
-
Sebastian Erdweg, Tijs van der Storm, Markus Völter, Laurence Tratt, Remi Bosman, William R. Cook, Albert Gerritsen, Angelo Hulshout, Steven Kelly, Alex Loh, Gabriël Konat, Pedro J. Molina, Martin Palatnik, Risto Pohjonen, Eugen Schindler, Klemens Schindler, Riccardo Solmi, Vlad A. Vergu, Eelco Visser, Kevin van der Vlist, Guido Wachsmuth, Jimi van der Woning.Language workbenches are environments for simplifying the creation and use of computer languages. The annual Language Workbench Challenge (LWC) was launched in 2011 to allow the many academic and industrial researchers in this area an opportunity to quantitatively and qualitatively compare their approaches. We first describe all four LWCs to date, before focussing on the approaches used, and results generated, during the third LWC. We give various empirical data for ten approaches from the third LWC. We present a generic feature model within which the approaches can be understood and contrasted. Finally, based on our experiences of the existing LWCs, we propose a number of benchmark problems for future LWCs.
-
A Language Designer's Workbench: A One-Stop-Shop for Implementation and Verification of Language DesignsEelco Visser, Guido Wachsmuth, Andrew P. Tolmach, Pierre Néron, Vlad A. Vergu, Augusto Passalaqua, Gabriël Konat.The realization of a language design requires multiple artifacts that redundantly encode the same information. This entails significant effort for language implementors, and often results in late detection of errors in language definitions. In this paper we present a proof-of-concept language designer's workbench that supports generation of IDEs, interpreters, and verification infrastructure from a single source. This constitutes a first milestone on the way to a system that fully automates language implementation and verification.
-
Sebastian Erdweg, Tijs van der Storm, Markus Völter, Meinte Boersma, Remi Bosman, William R. Cook, Albert Gerritsen, Angelo Hulshout, Steven Kelly, Alex Loh, Gabriël Konat, Pedro J. Molina, Martin Palatnik, Risto Pohjonen, Eugen Schindler, Klemens Schindler, Riccardo Solmi, Vlad A. Vergu, Eelco Visser, Kevin van der Vlist, Guido Wachsmuth, Jimi van der Woning.Language workbenches are tools that provide high-level mechanisms for the implementation of (domain-specific) languages. Language workbenches are an active area of research that also receives many contributions from industry. To compare and discuss existing language workbenches, the annual Language Workbench Challenge was launched in 2011. Each year, participants are challenged to realize a given domain-specific language with their workbenches as a basis for discussion and comparison. In this paper, we describe the state of the art of language workbenches as observed in the previous editions of the Language Workbench Challenge. In particular, we capture the design space of language workbenches in a feature model and show where in this design space the participants of the 2013 Language Workbench Challenge reside. We compare these workbenches based on a DSL for questionnaires that was realized in all workbenches.
-
Software is rapidly moving from the desktop to the Web. The Web provides a generic user interface that allows ubiquitous access, instant collaboration, integration with other online services, and avoids installation and configuration on desktop computers. For software development, the Web presents a shift away from developer workstations as a silo, and has the promise of closer collaboration and improved feedback through innovations in Web-based interactive development environments (IDEs). Moving IDEs to the Web is not just a matter of porting desktop IDEs; a fundamental reconsideration of the IDE architecture is necessary in order to realize the full potential that the combination of modern IDEs and the Web can offer. This paper discusses research challenges and opportunities in this area, guided by a pilot study of a web IDE implementation.
The Spoofax Language Workbench
 The Spoofax Language Workbench is a programming environment for the development of (domain-specific) programming languages using high-level declarative meta-languages for syntax (SDF3), static semantics (Statix), dynamic semantics (DynSem), program analysis (FlowSpec), program transformation (Stratego), and language testing (SPT). Spoofax supports live language development, so that one can define and use the language under development in the same environment. The Spoofax meta-languages are bootstrapped, i.e. developed using Spoofax itself. Spoofax is a testbed for experiments in meta-language design and programming environment architecture.
[More about Spoofax]
The Spoofax Language Workbench is a programming environment for the development of (domain-specific) programming languages using high-level declarative meta-languages for syntax (SDF3), static semantics (Statix), dynamic semantics (DynSem), program analysis (FlowSpec), program transformation (Stratego), and language testing (SPT). Spoofax supports live language development, so that one can define and use the language under development in the same environment. The Spoofax meta-languages are bootstrapped, i.e. developed using Spoofax itself. Spoofax is a testbed for experiments in meta-language design and programming environment architecture.
[More about Spoofax]
-
It is common practice to bootstrap compilers of programming languages. By using the compiled language to implement the compiler, compiler developers can code in their own high-level language and gain a large-scale test case. In this paper, we investigate bootstrapping of compiler-compilers as they occur in language workbenches. Language workbenches support the development of compilers through the application of multiple collaborating domain-specific meta-languages for defining a language's syntax, analysis, code generation, and editor support. We analyze the bootstrapping problem of language workbenches in detail, propose a method for sound bootstrapping based on fixpoint compilation, and show how to conduct breaking meta-language changes in a bootstrapped language workbench. We have applied sound bootstrapping to the Spoofax language workbench and report on our experience.
-
IDEs are essential for programming language developers, and state-of-the-art IDE support is mandatory for programming languages to be successful. Although IDE features for mainstream programming languages are typically implemented manually, this often isn't feasible for programming languages that must be developed with significantly fewer resources. The Spoofax language workbench is a platform for developing textual programming languages with state-of-the-art IDE support. Spoofax is a comprehensive environment that integrates syntax definition, name binding, type analysis, program transformation, code generation, and declarative specification of IDE components. It also provides high-level languages for each of these aspects. These languages are highly declarative, abstracting over the implementation of IDE features and letting engineers focus on language design.
-
Sebastian Erdweg, Lennart C. L. Kats, Tillmann Rendel, Christian Kästner, Klaus Ostermann, Eelco Visser.Large software projects consist of code written in a multitude of different (possibly domain-specific) languages, which are often deeply interspersed even in single files. While many proposals exist on how to integrate languages semantically and syntactically, the question of how to support this scenario in integrated development environments (IDEs) remains open: How can standard IDE services, such as syntax highlighting, outlining, or reference resolving, be provided in an extensible and compositional way, such that an open mix of languages is supported in a single file? Based on our library-based syntactic extension language for Java, SugarJ, we propose to make IDEs extensible by organizing editor services in editor libraries. Editor libraries are libraries written in the object language, SugarJ, and hence activated and composed through regular import statements on a file-by-file basis. We have implemented an IDE for editor libraries on top of SugarJ and the Eclipse-based Spoofax language workbench. We have validated editor libraries by evolving this IDE into a fully-fledged and schema-aware XML editor as well as an extensible Latex editor, which we used for writing this paper.
-
Spoofax is a language workbench for efficient, agile development of textual domain-specific languages with state-of-the-art IDE support. Spoofax integrates language processing techniques for parser generation, meta-programming, and IDE development into a single environment. It uses concise, declarative specifications for languages and IDE services. In this paper we describe the architecture of Spoofax and introduce idioms for high-level specifications of language semantics using rewrite rules, showing how analyses can be reused for transformations, code generation, and editor services such as error marking, reference resolving, and content completion. The implementation of these services is supported by language-parametric editor service classes that can be dynamically loaded by the Eclipse IDE, allowing new languages to be developed and used side-by-side in the same Eclipse environment.
The ASF+SDF Meta-Environment
The ASF+SDF Meta-Environment was a language workbench avant la lettre developed at CWI and the University of Amsterdam in the group of Paul Klint. It was based on the algebraic specification formalism ASF and the syntax definition formalism SDF. ASF equations were interpreted as term rewrite rules. SDF parsing was based on the Generalized-LR parsing algorithm. I contributed SDF2, a reimplementation of SDF based on Scannerless GLR. The Stratego transformation language was inspired by my experience with ASF.
-
Mark G. J. van den Brand, Arie van Deursen, Jan Heering, H. A. de Jong, Merijn de Jonge, Tobias Kuipers, Paul Klint, Leon Moonen, Pieter A. Olivier, Jeroen Scheerder, Jurgen J. Vinju, Eelco Visser, Joost Visser.The Asf+Sdf Meta-environment is an interactive development environment for the automatic generation of interactive systems for constructing language definitions and generating tools for them. Over the years, this system has been used in a variety of academic and commercial projects ranging from formal program manipulation to conversion of COBOL systems. Since the existing implementation of the Meta-environment started exhibiting more and more characteristics of a legacy system, we decided to build a completely new, component-based, version. We demonstrate this new system and stress its open architecture.
Syntax Definition and Parsing
Goal: To support the declarative specification of all syntactic aspects of a programming language in a single source and derive a wide range of efficient syntactic processors from that specification.
-
Syntax definitions are pervasive in modern software systems, and serve as the basis for language processing tools like parsers and compilers. Mainstream parser generators pose restrictions on syntax definitions that follow from their implementation algorithm. They hamper evolution, maintainability, and compositionality of syntax definitions. The pureness and declarativity of syntax definitions is lost. We analyze how these problems arise for different aspects of syntax definitions, discuss their consequences for language engineers, and show how the pure and declarative nature of syntax definitions can be regained.
The Syntax Definition Formalism SDF3
 The Syntax Definition Formalism SDF3 supports declarative specification of all syntactic aspects of a programming language in a single source from which a wide range of syntactic processors can be derived. SDF3 inherits from SDF2 character-level grammars, modular syntax definition, the support for language composition, and its implementation based on scannerless parsing. It extends SDF2 with template productions to integrate pretty-printing directives, constructor definitions for construction of abstract syntax trees, and layout constraints for the definition of layout sensitive languages. SDF3 improves the semantics of declarative disambiguation rules to be sound and complete. The SDF3 implementation supports incremental parsing, derivation of pretty-printers, syntax-aware editors, and syntactic code completion.
[More about SDF3]
The Syntax Definition Formalism SDF3 supports declarative specification of all syntactic aspects of a programming language in a single source from which a wide range of syntactic processors can be derived. SDF3 inherits from SDF2 character-level grammars, modular syntax definition, the support for language composition, and its implementation based on scannerless parsing. It extends SDF2 with template productions to integrate pretty-printing directives, constructor definitions for construction of abstract syntax trees, and layout constraints for the definition of layout sensitive languages. SDF3 improves the semantics of declarative disambiguation rules to be sound and complete. The SDF3 implementation supports incremental parsing, derivation of pretty-printers, syntax-aware editors, and syntactic code completion.
[More about SDF3]
-
SDF3 is a syntax definition formalism that extends plain context-free grammars with features such as constructor declarations, declarative disambiguation rules, character-level grammars, permissive syntax, layout constraints, formatting templates, placeholder syntax, and modular composition. These features support the multi-purpose interpretation of syntax definitions, including derivation of type schemas for abstract syntax tree representations, scannerless generalized parsing of the full class of context-free grammars, error recovery, layout-sensitive parsing, parenthesization and formatting, and syntactic completion. This paper gives a high level overview of SDF3 by means of examples and provides a guide to the literature for further details.
-
Declarative specification of indentation rules: a tooling perspective on parsing and pretty-printing layout-sensitive languagesIn layout-sensitive languages, the indentation of an expression or statement can influence how a program is parsed. While some of these languages (e.g., Haskell and Python) have been widely adopted, there is little support for software language engineers in building tools for layout-sensitive languages. As a result, parsers, pretty-printers, program analyses, and refactoring tools often need to be handwritten, which decreases the maintainability and extensibility of these tools. Even state-of-the-art language workbenches have little support for layout-sensitive languages, restricting the development and prototyping of such languages. In this paper, we introduce a novel approach to declarative specification of layout-sensitive languages using layout declarations. Layout declarations are high-level specifications of indentation rules that abstract from low-level technicalities. We show how to derive an efficient layout-sensitive generalized parser and a corresponding pretty-printer automatically from a language specification with layout declarations. We validate our approach in a case-study using a syntax definition for the Haskell programming language, investigating the performance of the generated parser and the correctness of the generated pretty-printer against 22191 Haskell files.
-
Principled syntactic code completion enables developers to change source code by inserting code templates, thus increasing developer efficiency and supporting language exploration. However, existing code completion systems are ad-hoc and neither complete nor sound. They are not complete and only provide few code templates for selected programming languages. They also are not sound and propose code templates that yield invalid programs when inserted.This paper presents a generic framework that automatically derives complete and sound syntactic code completion from the syntax definition of arbitrary languages. A key insight of our work is to provide an explicit syntactic representation for incomplete programs using placeholders. This enables us to address the following challenges for code completion separately: (i) completing incomplete programs by replacing placeholders with code templates, (ii) injecting placeholders into complete programs to make them incomplete, and (iii) introducing lexemes and placeholders into incorrect programs through error-recovery parsing to make them correct so we can apply one of the previous strategies. We formalize our framework and provide an implementation in the Spoofax Language Workbench.
-
Syntax discoverability has been a crucial advantage of structure editors for new users of a language. Despite this advantage, structure editors have not been widely adopted. Based on immediate parsing and analyses, modern textual code editors are also increasingly syntax-aware: structure and textual editors are converging into a new editing paradigm that combines text and templates. Current text-based language workbenches require redundant specification of the ingredients for a template-based editor, which is detrimental to the quality of syntactic completion, as consistency and completeness of the definition cannot be guaranteed. In this paper we describe the design and implementation of a specification language for syntax definition based on templates. It unifies the specification of parsers, unparsers and template-based editors. We evaluate the template language by application to two domain-specific languages used for tax benefits and mobile applications.
Declarative Disambiguation
I developed a theory of disambiguation of ambiguous (context-free) grammars that defines disambiguation separately from parsing, as a filter on a set of parse trees. This allows the reasoning about the semantics of disambiguation techniques and the correctness of implementations of disambiguation in parser generators or parsers. One application is the treatment of associativity and priority in LR parser generation for character-level grammars.
-
Associativity and priority are well known techniques to disambiguate expression grammars. In recent work we develop a direct semantics for disambiguation by associativity and priority rules and prove that a safe and complete disambiguation relation produces a safe and complete disambiguation. The proof approach relies on a correspondence between disambiguation and term rewriting such that safety of disambiguation corresponds to termination of the rewrite system and completeness of disambiguation correspond to confluence of the rewrite system. In this extended abstract we illustrate that approach using diagrams.
-
Context Context-free grammars are widely used for language prototyping and implementation. They allow formalizing the syntax of domain-specific or general-purpose programming languages concisely and declaratively. However, the natural and concise way of writing a context-free grammar is often ambiguous. Therefore, grammar formalisms support extensions in the form of declarative disambiguation rules to specify operator precedence and associativity, solving ambiguities that are caused by the subset of the grammar that corresponds to expressions. Inquiry Implementing support for declarative disambiguation within a parser typically comes with one or more of the following limitations in practice: a lack of parsing performance, or a lack of modularity (i.e., disallowing the composition of grammar fragments of potentially different languages). The latter subject is generally addressed by scannerless generalized parsers. We aim to equip scannerless generalized parsers with novel disambiguation methods that are inherently performant, without compromising the concerns of modularity and language composition. Approach In this paper, we present a novel low-overhead implementation technique for disambiguating deep associativity and priority conflicts in scannerless generalized parsers with lightweight data-dependency. Knowledge Ambiguities with respect to operator precedence and associativity arise from combining the various operators of a language. While shallow conflicts can be resolved efficiently by one-level tree patterns, deep conflicts require more elaborate techniques, because they can occur arbitrarily nested in a tree. Current state-of-the-art approaches to solving deep priority conflicts come with a severe performance overhead. Grounding We evaluated our new approach against state-of-the-art declarative disambiguation mechanisms. By parsing a corpus of popular open-source repositories written in Java and OCaml, we found that our approach yields speedups of up to 1.73x over a grammar rewriting technique when parsing programs with deep priority conflicts—with a modest overhead of 1–2 % when parsing programs without deep conflicts. Importance A recent empirical study shows that deep priority conflicts are indeed wide-spread in real-world programs. The study shows that in a corpus of popular OCaml projects on Github, up to 17 % of the source files contain deep priority conflicts. However, there is no solution in the literature that addresses efficient disambiguation of deep priority conflicts, with support for modular and composable syntax definitions.
-
Context-free grammars are suitable for formalizing the syntax of programming languages concisely and declaratively. Thus, such grammars are often found in reference manuals of programming languages, and used in language workbenches for language prototyping. However, the natural and concise way of writing a context-free grammar is often ambiguous. Safe and complete declarative disambiguation of operator precedence and associativity conflicts guarantees that all ambiguities arising from combining the operators of the language are resolved. Ambiguities can occur due to shallow conflicts, which can be captured by one-level tree patterns, and deep conflicts, which require more elaborate techniques. Approaches to solve deep priority conflicts include grammar transformations, which may result in large unambiguous grammars, or may require adapted parser technologies to include data-dependency tracking at parse time. In this paper we study deep priority conflicts "in the wild". We investigate the efficiency of grammar transformations to solve deep priority conflicts by using a lazy parse table generation technique. On top of lazily-generated parse tables, we define metrics, aiming to answer how often deep priority conflicts occur in real-world programs and to what extent programmers explicitly disambiguate programs themselves. By applying our metrics to a small corpus of popular open-source repositories we found that in OCaml, up to 17% of the source files contain deep priority conflicts.
-
In meta-programming with concrete object syntax, meta programs can be written using the concrete syntax of manipulated programs. Quotations of concrete syntax fragments and anti-quotations for meta-level expressions and variables are used to manipulate the abstract representation of programs. These small, isolated fragments are often ambiguous and must be explicitly disambiguated with quotation tags or types, using names from the non-terminals of the object language syntax. Discoverability of these names has been an open issue, as they depend on the (grammar) implementation and are not part of the concrete syntax of a language. Based on advances in interactive development environments, we introduce interactive disambiguation to address this issue, providing real-time feedback and proposing quick fixes in case of ambiguities.
-
In this paper we present the fusion of generalized LR parsing and scannerless parsing. This combination supports syntax definitions in which all aspects (lexical and context-free) of the syntax of a language are defined explicitly in one formalism. Furthermore, there are no restrictions on the class of grammars, thus allowing a natural syntax tree structure. Ambiguities that arise through the use of unrestricted grammars are handled by explicit disambiguation constructs, instead of implicit defaults that are taken by traditional scanner and parser generators. Hence, a syntax definition becomes a full declarative description of a language. Scannerless generalized LR parsing is a viable technique that has been applied in various industrial and academic projects.
-
Disambiguation methods for context-free grammars enable concise specification of programming languages by ambiguous grammars. A disambiguation filter is a function that selects a subset from a set of parse trees---the possible parse trees for an ambiguous sentence. The framework of filters provides a declarative description of disambiguation methods independent of parsing. Although filters can be implemented straightforwardly as functions that prune the parse forest produced by some generalized, this can be too inefficient for practical applications. In this paper the optimization of parsing schemata, a framework for high-level description of parsing algorithms, by disambiguation filters is considered in order to find efficient parsing algorithms for declaratively specified disambiguation methods. As a case study the optimization of the parsing schema of Earley's parsing algorithm by two filters is investigated. The main result is a technique for generation of efficient LR-like parsers for ambiguous grammars modulo priorities.
-
An ambiguous context-free grammar defines a language in which some sentences have multiple interpretations. For conciseness, ambiguous context-free grammars are frequently used to define even completely unambiguous languages and numerous disambiguation methods exist for specifying which interpretation is the intended one for each sentence. The existing methods can be divided in `parser specific' methods that describe how some parsing technique deals with ambiguous sentences and `logical' methods that describe the intended interpretation without reference to a specific parsing technique. We propose a framework of \em filters\/ to describe and compare a wide range of disambiguation problems in a parser-independent way. A filter is a function that selects from a set of parse trees (the canonical representation of the interpretations of a sentence) the intended trees. The framework enables us to define several general properties of disambiguation methods. The expressive power of filters is illustrated by several case studies. Finally, a start is made with the study of efficient implementation techniques for filters by exploiting the commutativity of parsing steps and filter steps for certain classes of filters.
Scannerless Generalized LR Parsing with (J)SGLR
 SGLR is an extension to character-level grammars of the Generalized-LR parsing algorithm of Rekers. The GLR aspect of the algorithm allows treating the entire class of context-free grammars. The algorithm is extended to character-level grammars by treating single characters as tokens. This requires lexical disambiguation to be performed by the parser. For that purpose, SGLR supports follow restrictions to model longest match and reject productions to model reserved words. The algorithm is further extended with support for layout constraints, syntactic completion, error recovery, error localization, error messages, and the production of abstract syntax trees. We maintain an implementation of SGLR in Java, but implementations exist in C, JavaScript, and Rust.
[More about SGLR]
SGLR is an extension to character-level grammars of the Generalized-LR parsing algorithm of Rekers. The GLR aspect of the algorithm allows treating the entire class of context-free grammars. The algorithm is extended to character-level grammars by treating single characters as tokens. This requires lexical disambiguation to be performed by the parser. For that purpose, SGLR supports follow restrictions to model longest match and reject productions to model reserved words. The algorithm is further extended with support for layout constraints, syntactic completion, error recovery, error localization, error messages, and the production of abstract syntax trees. We maintain an implementation of SGLR in Java, but implementations exist in C, JavaScript, and Rust.
[More about SGLR]
-
Context Context-free grammars are widely used for language prototyping and implementation. They allow formalizing the syntax of domain-specific or general-purpose programming languages concisely and declaratively. However, the natural and concise way of writing a context-free grammar is often ambiguous. Therefore, grammar formalisms support extensions in the form of declarative disambiguation rules to specify operator precedence and associativity, solving ambiguities that are caused by the subset of the grammar that corresponds to expressions. Inquiry Implementing support for declarative disambiguation within a parser typically comes with one or more of the following limitations in practice: a lack of parsing performance, or a lack of modularity (i.e., disallowing the composition of grammar fragments of potentially different languages). The latter subject is generally addressed by scannerless generalized parsers. We aim to equip scannerless generalized parsers with novel disambiguation methods that are inherently performant, without compromising the concerns of modularity and language composition. Approach In this paper, we present a novel low-overhead implementation technique for disambiguating deep associativity and priority conflicts in scannerless generalized parsers with lightweight data-dependency. Knowledge Ambiguities with respect to operator precedence and associativity arise from combining the various operators of a language. While shallow conflicts can be resolved efficiently by one-level tree patterns, deep conflicts require more elaborate techniques, because they can occur arbitrarily nested in a tree. Current state-of-the-art approaches to solving deep priority conflicts come with a severe performance overhead. Grounding We evaluated our new approach against state-of-the-art declarative disambiguation mechanisms. By parsing a corpus of popular open-source repositories written in Java and OCaml, we found that our approach yields speedups of up to 1.73x over a grammar rewriting technique when parsing programs with deep priority conflicts—with a modest overhead of 1–2 % when parsing programs without deep conflicts. Importance A recent empirical study shows that deep priority conflicts are indeed wide-spread in real-world programs. The study shows that in a corpus of popular OCaml projects on Github, up to 17 % of the source files contain deep priority conflicts. However, there is no solution in the literature that addresses efficient disambiguation of deep priority conflicts, with support for modular and composable syntax definitions.
-
Declarative specification of indentation rules: a tooling perspective on parsing and pretty-printing layout-sensitive languagesIn layout-sensitive languages, the indentation of an expression or statement can influence how a program is parsed. While some of these languages (e.g., Haskell and Python) have been widely adopted, there is little support for software language engineers in building tools for layout-sensitive languages. As a result, parsers, pretty-printers, program analyses, and refactoring tools often need to be handwritten, which decreases the maintainability and extensibility of these tools. Even state-of-the-art language workbenches have little support for layout-sensitive languages, restricting the development and prototyping of such languages. In this paper, we introduce a novel approach to declarative specification of layout-sensitive languages using layout declarations. Layout declarations are high-level specifications of indentation rules that abstract from low-level technicalities. We show how to derive an efficient layout-sensitive generalized parser and a corresponding pretty-printer automatically from a language specification with layout declarations. We validate our approach in a case-study using a syntax definition for the Haskell programming language, investigating the performance of the generated parser and the correctness of the generated pretty-printer against 22191 Haskell files.
-
Integrated development environments (IDEs) increase programmer productivity, providing rapid, interactive feedback based on the syntax and semantics of a language. Unlike conventional parsing algorithms, scannerless generalized-LR parsing supports the full set of context-free grammars, which is closed under composition, and hence can parse languages composed from separate grammar modules. To apply this algorithm in an interactive environment, this paper introduces a novel error recovery mechanism. Our approach is language-independent, and relies on automatic derivation of recovery rules from grammars. By taking layout information into consideration it can efficiently suggest natural recovery suggestions.
-
Technical report P9707, Programming Research Group, University of Amsterdam, 1997 [pdf, bib, researchr, abstract]Current deterministic parsing techniques have a number of problems. These include the limitations of parser generators for deterministic languages and the complex interface between scanner and parser. Scannerless parsing is a parsing technique in which lexical and context-free syntax are integrated into one grammar and are all handled by a single context-free analysis phase. This approach has a number of advantages including discarding of the scanner and lexical disambiguation by means of the context in which a lexical token occurs, Scannerless parsing generates a number of interesting problems as well. Integrated grammars do not fit the requirements of the conventional deterministic parsing techniques. A plain context-free grammar formalism leads to unwieldy grammars. if all lexical information is included. Lexical disambiguation needs to be reformulated for use in context-free parsing. The scannerless generalized-LR parsing approach presented in this paper solves these problems. Grammar normalization is used to support an expressive grammar formalism without complicating the underlying machinery. Follow restrictions are used to express longest match lexical disambiguation. Reject productions are used to express the prefer keywords rule for lexical disambiguation. The SLR parser generation algorithm is adapted to implement disambiguation by general priority and associativity declarations and to interpret follow restrictions. Generalized-LR parsing is used to provide dynamic lookahead and to support parsing of arbitrary context-free grammars including ambiguous ones. An adaptation of the GLR algorithm supports the interpretation of grammars with reject productions.
Syntactic Language Composition (MetaBorg)
Support the combination of languages or language libraries into composite language. language union, language extension, language embedding, meta-programming, parse table composition.
-
Domain-specific languages (DSLs) provide high expressive power focused on a particular problem domain. They provide linguistic abstractions and specialized syntax specifically designed for a domain, allowing developers to avoid boilerplate code and low-level implementation details. Language workbenches are tools that integrate all aspects of the definition of domain-specific or general-purpose software languages and the creation of a programming environment from such a definition. To count as a language workbench, a tool needs to satisfy basic requirements for the integrated definition of syntax, semantics, and editor services, and preferably also support language extension and composition. Within these requirements there is ample room for variation in the design of a language workbench. In this tutorial, we give an introduction to the state of the art in textual DSLs and language workbenches. We discuss the main requirements and variation points in the design of language workbenches, and describe two points in the design space using two state-of-the-art language workbenches. Spoofax is an example of a parser-based language workbench, while MPS represents language workbenches based on projectional editors.
-
Software written in one language often needs to construct sentences in another language, such as SQL queries, XML output, or shell command invocations. This is almost always done using unhygienic string manipulation, the concatenation of constants and client-supplied strings. A client can then supply specially crafted input that causes the constructed sentence to be interpreted in an unintended way, leading to an injection attack. We describe a more natural style of programming that yields code that is impervious to injections by construction. Our approach embeds the grammars of the guest languages (e.g. SQL) into that of the host language (e.g. Java) and automatically generates code that maps the embedded language to constructs in the host language that reconstruct the embedded sentences, adding escaping functions where appropriate. This approach is generic, meaning that it can be applied with relative ease to any combination of context-free host and guest languages.
-
Module systems, separate compilation, deployment of binary components, and dynamic linking have enjoyed wide acceptance in programming languages and systems. In contrast, the syntax of languages is usually defined in a non-modular way, cannot be compiled separately, cannot easily be combined with the syntax of other languages, and cannot be deployed as a component for later composition. Grammar formalisms that do support modules use whole program compilation. Current extensible compilers focus on source-level extensibility, which requires users to compile the compiler with a specific configuration of extensions. A compound parser needs to be generated for every combination of extensions. The generation of parse tables is expensive, which is a particular problem when the composition configuration is not fixed to enable users to choose language extensions. In this paper we introduce an algorithm for parse table composition to support separate compilation of grammars to parse table components. Parse table components can be composed (linked) efficiently at runtime, i.e. just before parsing. While the worst-case time complexity of parse table composition is exponential (like the complexity of parse table generation itself), for realistic language combination scenarios involving grammars for real languages, our parse table composition algorithm is an order of magnitude faster than computation of the parse table for the combined grammars.
-
The transformation language Stratego provides high-level abstractions for implementation of a wide range of transformations. Our aim is to integrate transformation in the software development process and make it available to programmers. This requires the transformations provided by the programming environment to be extensible. This paper presents a case study in the implementation of extensible programming environments using Stratego, by developing a small collection of language extensions and several typical transformations for these languages.
-
Concrete syntax for objects: domain-specific language embedding and assimilation without restrictionsApplication programmer's interfaces give access to domain knowledge encapsulated in class libraries without providing the appropriate notation for expressing domain composition. Since object-oriented languages are designed for extensibility and reuse, the language constructs are often sufficient for expressing domain abstractions at the semantic level. However, they do not provide the right abstractions at the syntactic level. In this paper we describe MetaBorg, a method for providing concrete syntax for domain abstractions to application programmers. The method consists of embedding domain-specific languages in a general purpose host language and assimilating the embedded domain code into the surrounding host code. Instead of extending the implementation of the host language, the assimilation phase implements domain abstractions in terms of existing APIs leaving the host language undisturbed. Indeed, MetaBorg can be considered a method for promoting APIs to the language level. The method is supported by proven and available technology, i.e. the syntax definition formalism SDF and the program transformation language and toolset Stratego/XT. We illustrate the method with applications in three domains: code generation, XML generation, and user-interface construction.
Syntax Definition with SDF2
character-level grammars, modular grammars, scannerless parsing, incremental parsing, declarative disambiguation rules. Support the combination of languages or language libraries into composite language.
-
Language prototyping is the activity of designing and testing definitions of new or existing computer languages. An important aspect of a language definition is the definition of its syntax. The subject of this thesis are new formalisms and techniques that support the development and prototyping of syntax definitions. There are four main subjects: (1) Techniques for parsing and disambiguation of context-free languages. (2) Design and implementation of a new syntax definition formalism. (3) Design of a multi-level algebraic specification formalism. (4) Study of polymorphic syntax definition.
Statics
Enable language designers to declaratively specify the name binding and typing rules of programming languages and automatically derive (efficient and incremental) type checkers from such specifications. Develop high-level model for representation of name binding rules and operations such as name resolution and refactoring, depending on name binding.
Type System Specification with Statix
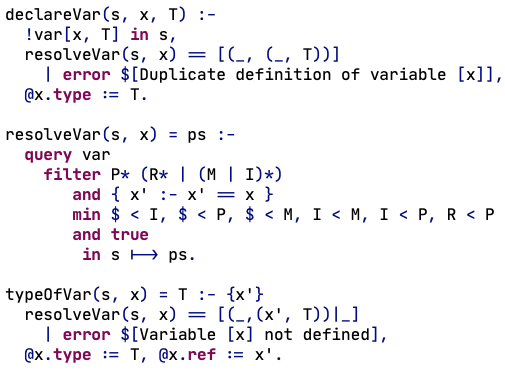 How to declaratively formalize the static semantics of programming languages and derive efficient type checkers? Enable language designers to declaratively specify the name binding and typing rules of programming languages and automatically derive (efficient and incremental) type checkers from such specifications. Develop high-level model for representation of name binding rules and operations such as name resolution and refactoring, depending on name binding.
[More about Statix]
How to declaratively formalize the static semantics of programming languages and derive efficient type checkers? Enable language designers to declaratively specify the name binding and typing rules of programming languages and automatically derive (efficient and incremental) type checkers from such specifications. Develop high-level model for representation of name binding rules and operations such as name resolution and refactoring, depending on name binding.
[More about Statix]
-
Knowing when to ask: sound scheduling of name resolution in type checkers derived from declarative specificationsThere is a large gap between the specification of type systems and the implementation of their type checkers, which impedes reasoning about the soundness of the type checker with respect to the specification. A vision to close this gap is to automatically obtain type checkers from declarative programming language specifications. This moves the burden of proving correctness from a case-by-case basis for concrete languages to a single correctness proof for the specification language. This vision is obstructed by an aspect common to all programming languages: name resolution. Naming and scoping are pervasive and complex aspects of the static semantics of programming languages. Implementations of type checkers for languages with name binding features such as modules, imports, classes, and inheritance interleave collection of binding information (i.e., declarations, scoping structure, and imports) and querying that information. This requires scheduling those two aspects in such a way that query answers are stable—i.e., they are computed only after all relevant binding structure has been collected. Type checkers for concrete languages accomplish stability using language-specific knowledge about the type system. In this paper we give a language-independent characterization of necessary and sufficient conditions to guarantee stability of name and type queries during type checking in terms of critical edges in an incomplete scope graph. We use critical edges to give a formal small-step operational semantics to a declarative specification language for type systems, that achieves soundness by delaying queries that may depend on missing information. This yields type checkers for the specified languages that are sound by construction—i.e., they schedule queries so that the answers are stable, and only accept programs that are name- and type-correct according to the declarative language specification. We implement this approach, and evaluate it against specifications of a small module and record language, as well as subsets of Java and Scala.
-
Towards Language-Parametric Semantic Editor Services Based on Declarative Type System Specifications (Brave New Idea Paper)Editor services assist programmers to more effectively write and comprehend code. Implementing editor services correctly is not trivial. This paper focuses on the specification of semantic editor services, those that use the semantic model of a program. The specification of refactorings is a common subject of study, but many other semantic editor services have received little attention. We propose a language-parametric approach to the definition of semantic editor services, using a declarative specification of the static semantics of the programming language, and constraint solving. Editor services are specified as constraint problems, and language specifications are used to ensure correctness. We describe our approach for the following semantic editor services: reference resolution, find usages, goto subclasses, code completion, and the extract definition refactoring. We do this in the context of Statix, a constraint language for the specification of type systems. We investigate the specification of editor services in terms of Statix constraints, and the requirements these impose on a suitable solver.
-
Scope graphs are a promising generic framework to model the binding structures of programming languages, bridging formalization and implementation, supporting the definition of type checkers and the automation of type safety proofs. However, previous work on scope graphs has been limited to simple, nominal type systems. In this paper, we show that viewing scopes as types enables us to model the internal structure of types in a range of non-simple type systems (including structural records and generic classes) using the generic representation of scopes. Further, we show that relations between such types can be expressed in terms of generalized scope graph queries. We extend scope graphs with scoped relations and queries. We introduce Statix, a new domain-specific meta-language for the specification of static semantics, based on scope graphs and constraints. We evaluate the scopes as types approach and the Statix design in case studies of the simply-typed lambda calculus with records, System F, and Featherweight Generic Java.
Name Resolution with Scope Graphs
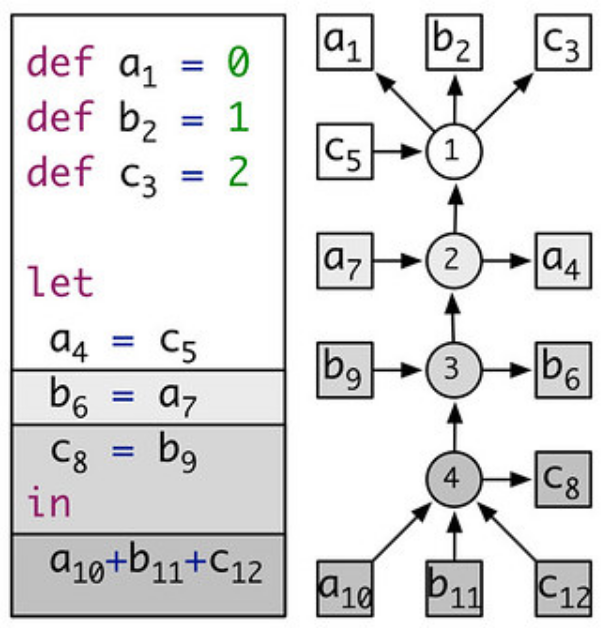 How to formalize the name binding rules of programming languages? We are developing scope graphs, a uniform framework for the representation of a wide range of name binding patterns in programming languages. A general theory of name resolution interprets scope graphs to resolve references to their corresponding declarations. Scope graphs are a core component of the Statix language for type system specification.
[More about Scope Graphs]
How to formalize the name binding rules of programming languages? We are developing scope graphs, a uniform framework for the representation of a wide range of name binding patterns in programming languages. A general theory of name resolution interprets scope graphs to resolve references to their corresponding declarations. Scope graphs are a core component of the Statix language for type system specification.
[More about Scope Graphs]
-
In previous work, we introduced scope graphs as a formalism for describing program binding structure and performing name resolution in an AST-independent way. In this paper, we show how to use scope graphs to build static semantic analyzers. We use constraints extracted from the AST to specify facts about binding, typing, and initialization. We treat name and type resolution as separate building blocks, but our approach can handle language constructs -- such as record field access -- for which binding and typing are mutually dependent. We also refine and extend our previous scope graph theory to address practical concerns including ambiguity checking and support for a wider range of scope relationships. We describe the details of constraint generation for a model language that illustrates many of the interesting static analysis issues associated with modules and records.
-
We describe a language-independent theory for name binding and resolution, suitable for programming languages with complex scoping rules including both lexical scoping and modules. We formulate name resolution as a two-stage problem. First a language-independent scope graph is constructed using language-specific rules from an abstract syntax tree. Then references in the scope graph are resolved to corresponding declarations using a language-independent resolution process. We introduce a resolution calculus as a concise, declarative, and languageindependent specification of name resolution. We develop a resolution algorithm that is sound and complete with respect to the calculus. Based on the resolution calculus we develop language-independent definitions of α-equivalence and rename refactoring. We illustrate the approach using a small example language with modules. In addition, we show how our approach provides a model for a range of name binding patterns in existing languages.
Name Binding Specification with NaBL
DSL for name binding [More about NaBL]
-
IDEs depend on incremental name and type analysis for responsive feedback for large projects. In this paper, we present a language-independent approach for incremental name and type analysis. Analysis consists of two phases. The first phase analyzes lexical scopes and binding instances and creates deferred analysis tasks. A task captures a single name resolution or type analysis step. Tasks might depend on other tasks and are evaluated in the second phase. Incrementality is supported on file and task level. When a file changes, only this file is recollected and only those tasks are reevaluated, which are affected by the changes in the collected data. The analysis does neither re-parse nor re-traverse unchanged files, even if they are affected by changes in other files. We implemented the approach as part of the Spoofax Language Workbench and evaluated it for the WebDSL web programming language.
-
In textual software languages, names are used to reference elements like variables, methods, classes, etc. Name resolution analyses these names in order to establish references between definition and use sites of elements. In this paper, we identify recurring patterns for name bindings in programming languages and introduce a declarative metalanguage for the specification of name bindings in terms of namespaces, definition sites, use sites, and scopes. Based on such declarative name binding specifications, we provide a language-parametric algorithm for static name resolution during compile-time. We discuss the integration of the algorithm into the Spoofax Language Workbench and show how its results can be employed in semantic editor services like reference resolution, constraint checking, and content completion.
Data-Flow Analysis with FlowSpec
Programs that are syntactically well-formed are not necessarily valid programs. Programming languages typically impose additional context-sensitive requirements on programs that cannot be captured in a syntax definition. Languages use data and control flow to check certain extra properties that fall outside of names and type systems. The FlowSpec ‘Flow Analysis Specification Language’ supports the specification of rules to define the static control flow of a language, and data flow analysis over that control flow. FlowSpec supports flow-sensitive intra-procedural data flow analysis. [More about FlowSpec]
-
FlowSpec: A declarative specification language for intra-procedural flow-Sensitive data-flow analysisData-flow analysis is the static analysis of programs to estimate their approximate run-time behavior or approximate intermediate run-time values. It is an integral part of modern language specifications and compilers. In the specification of static semantics of programming languages, the concept of data-flow allows the description of well-formedness such as definite assignment of a local variable before its first use. In the implementation of compiler back-ends, data-flow analyses inform optimizations. Data-flow analysis has an established theoretical foundation. What lags behind is implementations of data-flow analysis in compilers, which are usually ad-hoc. This makes such implementations difficult to extend and maintain. In previous work researchers have proposed higher-level formalisms suitable for whole-program analysis in a separate tool, incremental analysis within editors, or bound to a specific intermediate representation. In this paper, we present FlowSpec, an executable formalism for specification of data-flow analysis. FlowSpec is a domain-specific language that enables direct and concise specification of data-flow analysis for programming languages, designed to express flow-sensitive, intra-procedural analyses. We define the formal semantics of FlowSpec in terms of monotone frameworks. We describe the design of FlowSpec using examples of standard analyses. We also include a description of our implementation of FlowSpec. In a case study we evaluate FlowSpec with the static analyses for Green-Marl, a domain-specific programming language for graph analytics.
-
We present FlowSpec, a declarative specification language for the domain of dataflow analysis. FlowSpec has declarative support for the specification of control flow graphs of programming languages, and dataflow analyses on these control flow graphs. We define the formal semantics of FlowSpec, which is rooted in Monotone Frameworks. We also discuss a prototype implementation of the language, built in the Spoofax Language Workbench. Finally, we evaluate the expressiveness and conciseness of the language with two case studies. These case studies are analyses for Green-Marl, an industrial, domain-specific language for graph processing. The first case study is a classical dataflow analysis, scaled to this full language. The second case study is a domain-specific analysis of Green-Marl.
Dynamics
Identify the building blocks of the dynamic semantics of programming languages to create a specification language that can be used to concisely define a wide range of languages, derive efficient execution engines, and serve as the basis for automatic type soundness proofs.
Type Sound Dynamic Semantics (AutoSound)
 A definitional interpreter defines the semantics of an object language in terms of the (well-known) semantics of a host language, enabling understanding and validation of the semantics through execution. Combining a definitional interpreter with a separate type system requires a separate type safety proof. An alternative approach, at least for pure object languages, is to use a dependently-typed language to encode the object language type system in the definition of the abstract syntax. Using such intrinsically-typed abstract syntax definitions allows the host language type checker to verify automatically that the interpreter satisfies type safety. Does this approach scale to larger and more realistic object languages, and in particular to languages with mutable state and objects?
[More about AutoSound]
A definitional interpreter defines the semantics of an object language in terms of the (well-known) semantics of a host language, enabling understanding and validation of the semantics through execution. Combining a definitional interpreter with a separate type system requires a separate type safety proof. An alternative approach, at least for pure object languages, is to use a dependently-typed language to encode the object language type system in the definition of the abstract syntax. Using such intrinsically-typed abstract syntax definitions allows the host language type checker to verify automatically that the interpreter satisfies type safety. Does this approach scale to larger and more realistic object languages, and in particular to languages with mutable state and objects?
[More about AutoSound]
-
An intrinsically-typed definitional interpreter is a concise specification of dynamic semantics, that is executable and type safe by construction. Unfortunately, scaling intrinsically-typed definitional interpreters to more complicated object languages often results in definitions that are cluttered with manual proof work. For linearly-typed languages (including session-typed languages) one has to prove that the interpreter, as well as all the operations on semantic components, treat values linearly. We present new methods and tools that make it possible to implement intrinsically-typed definitional interpreters for linearly-typed languages in a way that hides the majority of the manual proof work. Inspired by separation logic, we develop reusable and composable abstractions for programming with linear operations using dependent types. Using these abstractions, we define interpreters for linear lambda calculi with strong references, concurrency, and session-typed communication in Agda.
-
A definitional interpreter defines the semantics of an object language in terms of the (well-known) semantics of a host language, enabling understanding and validation of the semantics through execution. Combining a definitional interpreter with a separate type system requires a separate type safety proof. An alternative approach, at least for pure object languages, is to use a dependently-typed language to encode the object language type system in the definition of the abstract syntax. Using such intrinsically-typed abstract syntax definitions allows the host language type checker to verify automatically that the interpreter satisfies type safety. Does this approach scale to larger and more realistic object languages, and in particular to languages with mutable state and objects? In this paper, we describe and demonstrate techniques and libraries in Agda that successfully scale up intrinsically-typed definitional interpreters to handle rich object languages with non-trivial binding structures and mutable state. While the resulting interpreters are certainly more complex than the simply-typed λ-calculus interpreter we start with, we claim that they still meet the goals of being concise, comprehensible, and executable, while guaranteeing type safety for more elaborate object languages. We make the following contributions: (1) A dependent-passing style technique for hiding the weakening of indexed values as they propagate through monadic code. (2) An Agda library for programming with scope graphs and frames, which provides a uniform approach to dealing with name binding in intrinsically-typed interpreters. (3) Case studies of intrinsically-typed definitional interpreters for the simply-typed λ-calculus with references (STLC+Ref) and for a large subset of Middleweight Java (MJ).
-
Semantic specifications do not make a systematic connection between the names and scopes in the static structure of a program and memory layout, and access during its execution. In this paper, we introduce a systematic approach to the alignment of names in static semantics and memory in dynamic semantics, building on the scope graph framework for name resolution. We develop a uniform memory model consisting of frames that instantiate the scopes in the scope graph of a program. This provides a language-independent correspondence between static scopes and run-time memory layout, and between static resolution paths and run-time memory access paths. The approach scales to a range of binding features, supports straightforward type soundness proofs, and provides the basis for a language-independent specification of sound reachability-based garbage collection.
Dynamic Semantics Specification with DynSem
The formal semantics of a programming language and its implementation are typically separately defined, with the risk of divergence such that properties of the formal semantics are not properties of the implementation. DynSem is a domain-specific language for the specification of the dynamic semantics of programming languages that aims at supporting both formal reasoning and efficient interpretation. [More about DynSem]
-
DynSem is a domain-specific language for concise specification of the dynamic semantics of programming languages, aimed at rapid experimentation and evolution of language designs. To maintain a short definition-to-execution cycle, DynSem specifications are meta-interpreted. Meta-interpretation introduces runtime overhead that is difficult to remove by using interpreter optimization frameworks such as the Truffle/Graal Java tools; previous work has shown order-of-magnitude improvements from applying Truffle/Graal to a meta-interpreter, but this is still far slower than what can be achieved with a language-specific interpreter. In this paper, we show how specifying the meta-interpreter using scope graphs, which encapsulate static name binding and resolution information, produces much better optimization results from Truffle/Graal. Furthermore, we identify that JIT compilation is hindered by large numbers of calls between small polymorphic rules and we introduce rule cloning to derive larger monomorphic rules at run time as a countermeasure. Our contributions improve the performance of DynSem-derived interpreters to within an order of magnitude of a handwritten language-specific interpreter.
-
DynSem is a domain-specific language for concise specification of the dynamic semantics of programming languages, aimed at rapid experimentation and evolution of language designs. DynSem specifications can be executed to interpret programs in the language under development. To enable fast turnaround during language development, we have developed a meta-interpreter for DynSem specifications, which requires minimal processing of the specification. In addition to fast development time, we also aim to achieve fast run times for interpreted programs. In this paper we present the design of a meta-interpreter for DynSem and report on experiments with JIT compiling the application of the meta-interpreter on the Graal VM. By interpreting specifications directly, we have minimal compilation overhead. By specializing pattern matches, maintaining call-site dispatch chains and using native control-flow constructs we gain significant run-time performance. We evaluate the performance of the meta-interpreter when applied to the Tiger language specification running a set of common benchmark programs. Specialization enables the Graal VM to JIT compile the meta-interpreter giving speedups of up to factor 15 over running on the standard Oracle Java VM.
-
The formal semantics of a programming language and its implementation are typically separately defined, with the risk of divergence such that properties of the formal semantics are not properties of the implementation. In this paper, we present DynSem, a domain-specific language for the specification of the dynamic semantics of programming languages that aims at supporting both formal reasoning and efficient interpretation. DynSem supports the specification of the operational semantics of a language by means of statically typed conditional term reduction rules. DynSem supports concise specification of reduction rules by providing implicit build and match coercions based on reduction arrows and implicit term constructors. DynSem supports modular specification by adopting implicit propagation of semantic components from I-MSOS, which allows omitting propagation of components such as environments and stores from rules that do not affect those. DynSem supports the declaration of native operators for delegation of aspects of the semantics to an external definition or implementation. DynSem supports the definition of auxiliary meta-functions, which can be expressed using regular reduction rules and are subject to semantic component propagation. DynSem specifications are executable through automatic generation of a Java-based AST interpreter.
Transformation
High-level specification of program transformations.
-
Program transformation is the mechanical manipulation of a program in order to improve it relative to some cost function and is understood broadly as the domain of computation where programs are the data. The natural basic building blocks of the domain of program transformation are transformation rules expressing a ?one-step? transformation on a fragment of a program. The ultimate perspective of research in this area is a high-level, language parametric, rule-based program transformation system, which supports a wide range of transformations, admitting efficient implementations that scale to large programs. This situation has not yet been reached, as trade-offs between different goals need to be made. This survey gives an overview of issues in rule-based program transformation systems, focusing on the expressivity of rule-based program transformation systems and in particular on transformation strategies available in various approaches. The survey covers term rewriting, extensions of basic term rewriting, tree parsing strategies, systems with programmable strategies, traversal strategies, and context-sensitive rules.
The Stratego Program Transformation Language
 Stratego is a language for defining transformations on abstract syntax trees. Stratego provides a term notation to construct and deconstruct trees and uses term rewriting to define transformations. Instead of applying all rewrite rules to all sub-terms, Stratego supports the definition of programmable rewriting strategies that control the application of rewrite rules using a language of basic strategy combinators. Important ingredients are combinators for generically visiting direct subtrees, which can be combined into a wide range of generic traversal strategies. Context sensitive transformations (such as function inlining) can be defined using scoped dynamic rewrite rewrite rules. Generic traversals have been adopted in other languages, in particular in the Scrap your Boilerplate pattern in Haskell.
[More about Stratego]
Stratego is a language for defining transformations on abstract syntax trees. Stratego provides a term notation to construct and deconstruct trees and uses term rewriting to define transformations. Instead of applying all rewrite rules to all sub-terms, Stratego supports the definition of programmable rewriting strategies that control the application of rewrite rules using a language of basic strategy combinators. Important ingredients are combinators for generically visiting direct subtrees, which can be combined into a wide range of generic traversal strategies. Context sensitive transformations (such as function inlining) can be defined using scoped dynamic rewrite rewrite rules. Generic traversals have been adopted in other languages, in particular in the Scrap your Boilerplate pattern in Haskell.
[More about Stratego]
-
Constructing Hybrid Incremental Compilers for Cross-Module Extensibility with an Internal Build SystemContext: Compilation time is an important factor in the adaptability of a software project. Fast recompilation enables cheap experimentation with changes to a project, as those changes can be tested quickly. Separate and incremental compilation has been a topic of interest for a long time to facilitate fast recompilation. Inquiry: Despite the benefits of an incremental compiler, such compilers are usually not the default. This is because incrementalization requires cross-cutting, complicated, and error-prone techniques such as dependency tracking, caching, cache invalidation, and change detection. Especially in compilers for languages with cross-module definitions and integration, correctly and efficiently implementing an incremental compiler can be a challenge. Retrofitting incrementality into a compiler is even harder. We address this problem by developing a compiler design approach that reuses parts of an existing non-incremental compiler to lower the cost of building an incremental compiler. It also gives an intuition into compiling difficult-to-incrementalize language features through staging. Approach: We use the compiler design approach presented in this paper to develop an incremental com- piler for the Stratego term-rewriting language. This language has a set of features that at first glance look incompatible with incremental compilation. Therefore, we treat Stratego as our critical case to demonstrate the approach on. We show how this approach decomposes the original compiler and has a solution to com- pile Stratego incrementally. The key idea on which we build our incremental compiler is to internally use an incremental build system to wire together the components we extract from the original compiler. Knowledge: The resulting compiler is already in use as a replacement of the original whole-program compiler. We find that the incremental build system inside the compiler is a crucial component of our approach. This allows a compiler writer to think in multiple steps of compilation, and combine that into a incremental compiler almost effortlessly. Normally, separate compilation à la C is facilitated by an external build system, where the programmer is responsible for managing dependencies between files. We reuse an existing sound and optimal incremental build system, and integrate its dependency tracking into the compiler. Grounding: The incremental compiler for Stratego is available as an artefact along with this article. We evaluate it on a large Stratego project to test its performance. The benchmark replays edits to the Stratego project from version control. These benchmarks are part of the artefact, packaged as a virtual machine image for easy reproducibility. Importance: Although we demonstrate our design approach on the Stratego programming language, we also describe it generally throughout this paper. Many currently used programming languages have a compiler that is much slower than necessary. Our design provides an approach to change this, by reusing an existing compiler and making it incremental within a reasonable amount of time.
-
The Stratego language supports program transformation by means of term rewriting with programmable rewriting strategies. Stratego's traversal primitives support concise definition of generic tree traversals. Stratego is a dynamically typed language because its features cannot be captured fully by a static type system. While dynamic typing makes for a flexible programming model, it also leads to unintended type errors, code that is harder to maintain, and missed opportunities for optimization. In this paper, we introduce a gradual type system for Stratego that combines the flexibility of dynamically typed generic programming, where needed, with the safety of statically declared and enforced types, where possible. To make sure that statically typed code cannot go wrong, all access to statically typed code from dynamically typed code is protected by dynamic type checks (casts). The type system is backwards compatible such that types can be introduced incrementally to existing Stratego programs. We formally define a type system for Core Gradual Stratego, discuss its implementation in a new type checker for Stratego, and present an evaluation of its impact on Stratego programs.
-
Transformations and semantic analysis for source-to-source transformations such as refactorings are most effectively implemented using an abstract representation of the source code. An intrinsic limitation of transformation techniques based on abstract syntax trees is the loss of layout, i.e. comments and whitespace. This is especially relevant in the context of refactorings, which produce source code for human consumption. In this paper, we present an algorithm for fully automatic source code reconstruction for source-to-source transformations. The algorithm preserves the layout and comments of the unaffected parts and reconstructs the indentation of the affected parts, using a set of clearly defined heuristic rules to handle comments.
-
The applicability of term rewriting to program transformation is limited by the lack of control over rule application and by the context-free nature of rewrite rules. The first problem is addressed by languages supporting user-definable rewriting strategies. The second problem is addressed by the extension of rewriting strategies with scoped dynamic rewrite rules. Dynamic rules are defined at run-time and can access variables available from their definition context. Rules defined within a rule scope are automatically retracted at the end of that scope. In this paper, we explore the design space of dynamic rules, and their application to transformation problems. The technique is formally defined by extending the operational semantics underlying the program transformation language Stratego, and illustrated by means of several program transformations in Stratego, including constant propagation, bound variable renaming, dead code elimination, function inlining, and function specialization.
-
Composing Source-to-Source Data-Flow Transformations with Rewriting Strategies and Dependent Dynamic Rewrite RulesData-flow transformations used in optimizing compilers are also useful in other programming tools such as code generators, aspect weavers, domain-specific optimizers, and refactoring tools. These applications require source-to-source transformations rather than transformations on a low-level intermediate representation. In this paper we describe the composition of source-to-source data-flow transformations in the program transformation language Stratego. The language supports the high-level specification of transformations by means of rewriting strategy combinators that allow a natural modeling of data- and control-flow without committing to a specific source language. Data-flow facts are propagated using dynamic rewriting rules. In particular, we introduce the concept of dependent dynamic rewrite rules for modeling the dependencies of data-flow facts on program entities such as variables. The approach supports the combination of analysis and transformation, the combination of multiple transformations, the combination with other types of transformations, and the correct treatment of variable binding constructs and lexical scope to avoid free variable capture.
-
We describe a language for defining term rewriting strategies, and its application to the production of program optimizers. Valid transformations on program terms can be described by a set of rewrite rules; rewriting strategies are used to describe when and how the various rules should be applied in order to obtain the desired optimization effects. Separating rules from strategies in this fashion makes it easier to reason about the behavior of the optimizer as a whole, compared to traditional monolithic optimizer implementations. We illustrate the expressiveness of our language by using it to describe a simple optimizer for an ML-like intermediate representation.The basic strategy language uses operators such as sequential composition, choice, and recursion to build transformers from a set of labeled unconditional rewrite rules. We also define an extended language in which the side-conditions and contextual rules that arise in realistic optimizer specifications can themselves be expressed as strategy-driven rewrites. We show that the features of the basic and extended languages can be expressed by breaking down the rewrite rules into their primitive building blocks, namely matching and building terms in variable binding environments. This gives us a low-level core language which has a clear semantics, can be implemented straightforwardly and can itself be optimized. The current implementation generates C code from a strategy specification.
Meta-Programming with Concrete Object Syntax
meta-programming with concrete object syntax
-
Software written in one language often needs to construct sentences in another language, such as SQL queries, XML output, or shell command invocations. This is almost always done using unhygienic string manipulation, the concatenation of constants and client-supplied strings. A client can then supply specially crafted input that causes the constructed sentence to be interpreted in an unintended way, leading to an injection attack. We describe a more natural style of programming that yields code that is impervious to injections by construction. Our approach embeds the grammars of the guest languages (e.g. SQL) into that of the host language (e.g. Java) and automatically generates code that maps the embedded language to constructs in the host language that reconstruct the embedded sentences, adding escaping functions where appropriate. This approach is generic, meaning that it can be applied with relative ease to any combination of context-free host and guest languages.
-
In meta-programming with concrete object syntax, meta programs can be written using the concrete syntax of manipulated programs. Quotations of concrete syntax fragments and anti-quotations for meta-level expressions and variables are used to manipulate the abstract representation of programs. These small, isolated fragments are often ambiguous and must be explicitly disambiguated with quotation tags or types, using names from the non-terminals of the object language syntax. Discoverability of these names has been an open issue, as they depend on the (grammar) implementation and are not part of the concrete syntax of a language. Based on advances in interactive development environments, we introduce interactive disambiguation to address this issue, providing real-time feedback and proposing quick fixes in case of ambiguities.
-
Language extensions increase programmer productivity by providing concise, often domain-specific syntax, and support for static verification of correctness, security, and style constraints. Language extensions can often be realized through translation to the base language, supported by preprocessors and extensible compilers. However, various kinds of extensions require further adaptation of a base compiler's internal stages and components, for example to support separate compilation or to make use of low-level primitives of the platform (e.g., jump instructions or unbalanced synchronization). To allow for a more loosely coupled approach, we propose an open compiler model based on normalization steps from a high-level language to a subset of it, the core language. We developed such a compiler for a mixed Java and (core) bytecode language, and evaluate its effectiveness for composition mechanisms such as traits, as well as statement-level and expression-level language extensions.
-
Software written in one language often needs to construct sentences in another language, such as SQL queries, XML output, or shell command invocations. This is almost always done using unhygienic string manipulation, the concatenation of constants and client-supplied strings. A client can then supply specially crafted input that causes the constructed sentence to be interpreted in an unintended way, leading to an injection attack. We describe a more natural style of programming that yields code that is impervious to injections by construction. Our approach embeds the grammars of the guest languages (e.g., SQL) into that of the host language (e.g., Java) and automatically generates code that maps the embedded language to constructs in the host language that reconstruct the embedded sentences, adding escaping functions where appropriate. This approach is generic, meaning that it can be applied with relative ease to any combination of host and guest languages.
-
In meta programming with concrete object syntax, object-level programs are composed from fragments written in concrete syntax. The use of small program fragments in such quotations and the use of meta-level expressions within these fragments (anti-quotation) often leads to ambiguities. This problem is usually solved through explicit disambiguation, resulting in considerable syntactic overhead. A few systems manage to reduce this overhead by using type information during parsing. Since this is hard to achieve with traditional parsing technology, these systems provide specific combinations of meta and object languages, and their implementations are difficult to reuse. In this paper, we generalize these approaches and present a language independent method for introducing concrete object syntax without explicit disambiguation. The method uses scannerless generalized-LR parsing to parse meta programs with embedded object-level fragments, which produces a forest of all possible parses. This forest is reduced to a tree by a disambiguating type checker for the meta language. To validate our method we have developed embeddings of several object languages in Java, including AspectJ and Java itself.
-
The transformation language Stratego provides high-level abstractions for implementation of a wide range of transformations. Our aim is to integrate transformation in the software development process and make it available to programmers. This requires the transformations provided by the programming environment to be extensible. This paper presents a case study in the implementation of extensible programming environments using Stratego, by developing a small collection of language extensions and several typical transformations for these languages.
-
Concrete syntax for objects: domain-specific language embedding and assimilation without restrictionsApplication programmer's interfaces give access to domain knowledge encapsulated in class libraries without providing the appropriate notation for expressing domain composition. Since object-oriented languages are designed for extensibility and reuse, the language constructs are often sufficient for expressing domain abstractions at the semantic level. However, they do not provide the right abstractions at the syntactic level. In this paper we describe MetaBorg, a method for providing concrete syntax for domain abstractions to application programmers. The method consists of embedding domain-specific languages in a general purpose host language and assimilating the embedded domain code into the surrounding host code. Instead of extending the implementation of the host language, the assimilation phase implements domain abstractions in terms of existing APIs leaving the host language undisturbed. Indeed, MetaBorg can be considered a method for promoting APIs to the language level. The method is supported by proven and available technology, i.e. the syntax definition formalism SDF and the program transformation language and toolset Stratego/XT. We illustrate the method with applications in three domains: code generation, XML generation, and user-interface construction.
-
AUTOBAYES is a fully automatic, schema-based program synthesis system for statistical data analysis applications. Its core component is a schema library, i.e., a collection of generic code templates with associated applicability constraints which are instantiated in a problem-specific way during synthesis. Currently, AUTOBAYE S is implemented in Prolog; the schemas thus use abstract syntax (i.e., Prolog terms) to formulate the templates. However, the conceptual distance between this abstract representation and the concrete syntax of the generated programs makes the schemas hard to create and maintain. In this paper we describe how AUTOBAYE S is retrofitted with concrete syn- tax. We show how it is integrated into Prolog and describe how the seamless interaction of concrete syntax fragments with AUTOBAYE S’s remaining “legacy” meta-programming kernel based on abstract syntax is achieved. We apply the approach to gradually migrate individual schemas without forcing a disruptive migration of the entire system to a different meta-programming language. First experiences show that a smooth migration can be achieved. Moreover, it can re- sult in a considerable reduction of the code size and improved readability of the code. In particular, abstracting out fresh-variable generation and second-order term construction allows the formulation of larger continuous fragments.
-
Meta programs manipulate structured representations, i.e., abstract syntax trees, of programs. The conceptual distance between the concrete syntax meta-programmers use to reason about programs and the notation for abstract syntax manipulation provided by general purpose (meta-) programming languages is too great for many applications. In this paper it is shown how the syntax definition formalism SDF can be employed to fit any meta-programming language with concrete syntax notation for composing and analyzing object programs. As a case study, the addition of concrete syntax to the program transformation language Stratego is presented. The approach is then generalized to arbitrary meta-languages.
C++ Transformation
transforming C++ programs
-
The use of a high-level, abstract coding style can greatly increase developer productivity. For numerical software, this can result in drastically reduced run-time performance. High-level, domain-specific optimisations can eliminate much of the overhead caused by an abstract coding style, but current compilers have poor support for domain-specific optimisation. In this paper we present CodeBoost, a source-to-source transformation tool for domain-specific optimisation of C++ programs. CodeBoost performs parsing, semantic analysis and pretty-printing, and transformations can be implemented either in the Stratego program transformation language, or as user-defined rewrite rules embedded within the C++ program. CodeBoost has been used with great success to optimise numerical applications written in the Sophus high-level coding style. We discuss the overall design of the CodeBoost transformation framework, and take a closer look at two important features of CodeBoost: user-defined rules and totem annotations. We also show briefly how CodeBoost is used to optimise Sophus code, resulting in applications that run twice as fast, or more.
Building Transformation Tools with Stratego/XT
 XT is a bundle of transformation tools that combines Stratego, a language for transformation of abstract syntax trees, with tools for other aspects of program transformation. Stratego only deals with transformation of programs represented by means of terms. Parsing and pretty-printing is provided by the XT bundle of transformation tools, which combines Stratego with the Syntax Definition Formalism SDF and the Generic Pretty-Printing Package GPP.
[More about Stratego/XT]
XT is a bundle of transformation tools that combines Stratego, a language for transformation of abstract syntax trees, with tools for other aspects of program transformation. Stratego only deals with transformation of programs represented by means of terms. Parsing and pretty-printing is provided by the XT bundle of transformation tools, which combines Stratego with the Syntax Definition Formalism SDF and the Generic Pretty-Printing Package GPP.
[More about Stratego/XT]
-
Stratego/XT is a language and toolset for program transformation. The Stratego language provides rewrite rules for expressing basic transformations, programmable rewriting strategies for controlling the application of rules, concrete syntax for expressing the patterns of rules in the syntax of the object language, and dynamic rewrite rules for expressing context-sensitive transformations, thus supporting the development of transformation components at a high level of abstraction. The XT toolset offers a collection of flexible, reusable transformation components, and tools for generating such components from declarative specifications. Complete program transformation systems are composed from these components.
-
Stratego/XT is a language and toolset for program transformation. The Stratego language provides rewrite rules for expressing basic transformations, programmable rewriting strategies for controlling the application of rules, concrete syntax for expressing the patterns of rules in the syntax of the object language, and dynamic rewrite rules for expressing context-sensitive transformations, thus supporting the development of transformation components at a high level of abstraction. The XT toolset offers a collection of flexible, reusable transformation components, as well as declarative languages for deriving new components. Complete program transformation systems are composed from these components. In this paper we give an overview of Stratego/XT 0.16.
-
Stratego/XT is a framework for the development of transformation systems aiming to support a wide range of program transformations. The framework consists of the transformation language Stratego and the XT collection of transformation tools. Stratego is based on the paradigm of rewriting under the control of programmable rewriting strategies. The XT tools provide facilities for the infrastructure of transformation systems including parsing and pretty-printing. The framework addresses the entire range of the development process; from the specification of transformations to their composition into transformation systems. This chapter gives an overview of the main ingredients involved in the composition of transformation systems with Stratego/XT, where we distinguish the abstraction levels of rules, strategies, tools, and systems.
Testing
Support testing of language processors. Generation of representative tests from language definitions.
Language Testing with SPT
 The SPoofax Testing language (SPT) allows language developers to test their language in a declarative way. It offers a language to express test cases for any textual language that you want to test, and a framework for executing those tests on language implementations created with Spoofax.
[More about SPT]
The SPoofax Testing language (SPT) allows language developers to test their language in a declarative way. It offers a language to express test cases for any textual language that you want to test, and a framework for executing those tests on language implementations created with Spoofax.
[More about SPT]
-
The reliability of compilers, interpreters, and development environments for programming languages is essential for effective software development and maintenance. They are often tested only as an afterthought. Languages with a smaller scope, such as domain-specific languages, often remain untested. General-purpose testing techniques and test case generation methods fall short in providing a low-threshold solution for test-driven language development. In this paper we introduce the notion of a language-parametric testing language (LPTL) that provides a reusable, generic basis for declaratively specifying language definition tests. We integrate the syntax, semantics, and editor services of a language under test into the LPTL for writing test inputs. This paper describes the design of an LPTL and the tool support provided for it, shows use cases using examples, and describes our implementation in the form of the Spoofax testing language.
Software Building and Deployment
Integrate build automation, programming languages, and programming environments to get sound incremental software construction at all levels of granularity.
Incremental Software Pipelines with PIE
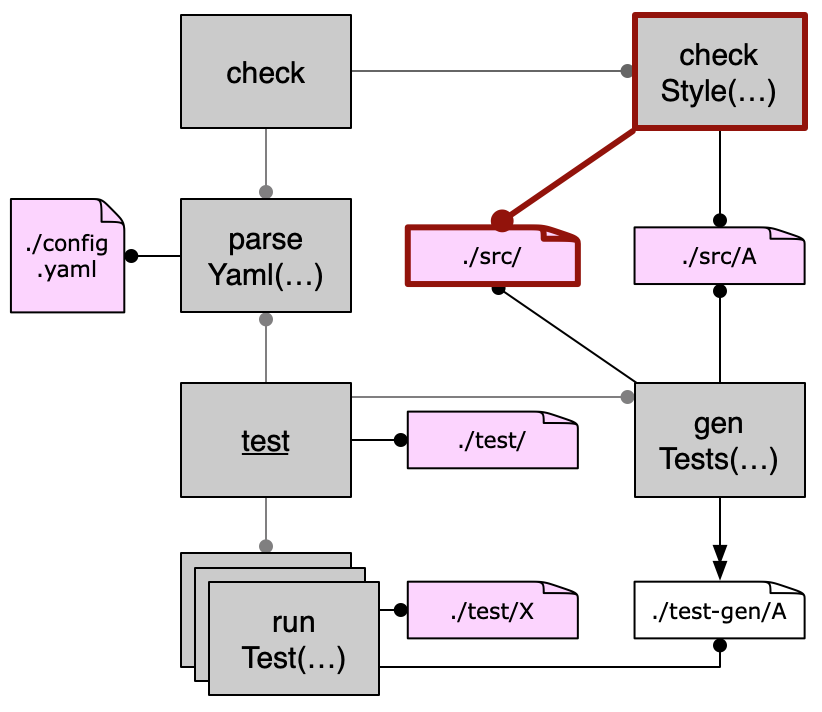 How to declaratively specify software pipelines for fine and coarse grained tasks and ensure their sound incremental execution? PIE is a domain-specific language and runtime for the specification of software pipelines and their incremental execution. PIE provides an expressive language for defining pipelines including dynamic dependencies, and guarantees efficient, precise and scalable incremental execution.
[More about PIE]
How to declaratively specify software pipelines for fine and coarse grained tasks and ensure their sound incremental execution? PIE is a domain-specific language and runtime for the specification of software pipelines and their incremental execution. PIE provides an expressive language for defining pipelines including dynamic dependencies, and guarantees efficient, precise and scalable incremental execution.
[More about PIE]
-
Constructing Hybrid Incremental Compilers for Cross-Module Extensibility with an Internal Build SystemContext: Compilation time is an important factor in the adaptability of a software project. Fast recompilation enables cheap experimentation with changes to a project, as those changes can be tested quickly. Separate and incremental compilation has been a topic of interest for a long time to facilitate fast recompilation. Inquiry: Despite the benefits of an incremental compiler, such compilers are usually not the default. This is because incrementalization requires cross-cutting, complicated, and error-prone techniques such as dependency tracking, caching, cache invalidation, and change detection. Especially in compilers for languages with cross-module definitions and integration, correctly and efficiently implementing an incremental compiler can be a challenge. Retrofitting incrementality into a compiler is even harder. We address this problem by developing a compiler design approach that reuses parts of an existing non-incremental compiler to lower the cost of building an incremental compiler. It also gives an intuition into compiling difficult-to-incrementalize language features through staging. Approach: We use the compiler design approach presented in this paper to develop an incremental com- piler for the Stratego term-rewriting language. This language has a set of features that at first glance look incompatible with incremental compilation. Therefore, we treat Stratego as our critical case to demonstrate the approach on. We show how this approach decomposes the original compiler and has a solution to com- pile Stratego incrementally. The key idea on which we build our incremental compiler is to internally use an incremental build system to wire together the components we extract from the original compiler. Knowledge: The resulting compiler is already in use as a replacement of the original whole-program compiler. We find that the incremental build system inside the compiler is a crucial component of our approach. This allows a compiler writer to think in multiple steps of compilation, and combine that into a incremental compiler almost effortlessly. Normally, separate compilation à la C is facilitated by an external build system, where the programmer is responsible for managing dependencies between files. We reuse an existing sound and optimal incremental build system, and integrate its dependency tracking into the compiler. Grounding: The incremental compiler for Stratego is available as an artefact along with this article. We evaluate it on a large Stratego project to test its performance. The benchmark replays edits to the Stratego project from version control. These benchmarks are part of the artefact, packaged as a virtual machine image for easy reproducibility. Importance: Although we demonstrate our design approach on the Stratego programming language, we also describe it generally throughout this paper. Many currently used programming languages have a compiler that is much slower than necessary. Our design provides an approach to change this, by reusing an existing compiler and making it incremental within a reasonable amount of time.
-
Context. Software development pipelines are used for automating essential parts of software engineering processes, such as build automation and continuous integration testing. In particular, interactive pipelines, which process events in a live environment such as an IDE, require timely results for low-latency feedback, and persistence to retain low-latency feedback between restarts. Inquiry. Developing an incrementalized and persistent version of a pipeline is one way to reduce feedback latency, but requires implementation of dependency tracking, cache invalidation, and other complicated and error-prone techniques. Therefore, interactivity complicates pipeline development if timeliness and persistence become responsibilities of the pipeline programmer, rather than being supported by the underlying system. Systems for programming incremental and persistent pipelines exist, but do not focus on ease of development, requiring a high degree of boilerplate, increasing development and maintenance effort. Approach. We develop Pipelines for Interactive Environments (PIE), a Domain-Specific Language (DSL), API, and runtime for developing interactive software development pipelines, where ease of development is a focus. The PIE DSL is a statically typed and lexically scoped language. PIE programs are compiled to programs implementing the API, which the PIE runtime executes in an incremental and persistent way. Knowledge. PIE provides a straightforward programming model that enables direct and concise expression of pipelines without boilerplate, reducing the development and maintenance effort of pipelines. Compiled pipeline programs can be embedded into interactive environments such as code editors and IDEs, enabling timely feedback at a low cost. Grounding. Compared to the state of the art, PIE reduces the code required to express an interactive pipeline by a factor of 6 in a case study on syntax-aware editors. Furthermore, we evaluate PIE in two case studies of complex interactive software development scenarios, demonstrating that PIE can handle complex interactive pipelines in a straightforward and concise way. Importance. Interactive pipelines are complicated software artifacts that power many important systems such as continuous feedback cycles in IDEs and code editors, and live language development in language workbenches. New pipelines, and evolution of existing pipelines, is frequently necessary. Therefore, a system for easily developing and maintaining interactive pipelines, such as PIE, is important.
-
Incremental build systems are essential for fast, reproducible software builds. Incremental build systems enable short feedback cycles when they capture dependencies precisely and selectively execute build tasks efficiently. A much overlooked feature of build systems is the expressiveness of the scripting language, which directly influences the maintainability of build scripts. In this paper, we present a new incremental build algorithm that allows build engineers to use a full-fledged programming language with explicit task invocation, value and file inspection facilities, and conditional and iterative language constructs. In contrast to prior work on incrementality for such programmable builds, our algorithm scales with the number of tasks affected by a change and is independent of the size of the software project being built. Specifically, our algorithm accepts a set of changed files, transitively detects and re-executes affected build tasks, but also accounts for new task dependencies discovered during building. We have evaluated the performance of our algorithm in a real-world case study and confirm its scalability.
-
It is common practice to bootstrap compilers of programming languages. By using the compiled language to implement the compiler, compiler developers can code in their own high-level language and gain a large-scale test case. In this paper, we investigate bootstrapping of compiler-compilers as they occur in language workbenches. Language workbenches support the development of compilers through the application of multiple collaborating domain-specific meta-languages for defining a language's syntax, analysis, code generation, and editor support. We analyze the bootstrapping problem of language workbenches in detail, propose a method for sound bootstrapping based on fixpoint compilation, and show how to conduct breaking meta-language changes in a bootstrapped language workbench. We have applied sound bootstrapping to the Spoofax language workbench and report on our experience.
Software Deployment with Nix/NixOS
Software deployment on Unix. Deployment in isolation. Concurrent installation of different versions of a system. Reliable garbage collection. [More about Nix]
-
Existing systems for software deployment are neither safe nor sufficiently flexible. Primary safety issues are the inability to enforce reliable specification of component dependencies, and the lack of support for multiple versions or variants of a component. This renders deployment operations such as upgrading or deleting components dangerous and unpredictable. A deployment system must also be flexible (i.e., policy-free) enough to support both centralised and local package management, and to allow a variety of mechanisms for transferring components. In this paper we present Nix, a deployment system that addresses these issues through a simple technique of using cryptographic hashes to compute unique paths for component instances.
-
The deployment of software components frequently fails because dependencies on other components are not declared explicitly or are declared imprecisely. This results in an incomplete reproduction of the environment necessary for proper operation, or in interference between incompatible variants. In this paper we show that these deployment hazards are similar to pointer hazards in memory models of programming languages and can be countered by imposing a memory management discipline on software deployment. Based on this analysis we have developed a generic, platform and language independent, discipline for deployment that allows precise dependency verification; exact identification of component variants; computation of complete closures containing all components on which a component depends; maximal sharing of components between such closures; and concurrent installation of revisions and variants of components. We have implemented the approach in the Nix deployment system, and used it for the deployment of a large number of existing Linux packages. We compare its effectiveness to other deployment systems.
Linguistic Abstractions for Web Programming
High-level specification of web applications abstracting from low-level implementation details. The WebDSL web programming language provides abstractions and consistency checking for data modeling, presentation, search, access control, and more.
Web Programming with WebDSL
 How to develop web applications without the boilerplate? WebDSL is a domain-specific language for development of web applications with a rich data model. The language supports separation of concerns by providing sub-languages catering for the different technical domains of web engineering, including data modeling, presentation, search, and access control. Linguistic integration of these sub-languages ensures seamless integration and static checking of the aspects comprising the definition of a web application.
[More about WebDSL]
How to develop web applications without the boilerplate? WebDSL is a domain-specific language for development of web applications with a rich data model. The language supports separation of concerns by providing sub-languages catering for the different technical domains of web engineering, including data modeling, presentation, search, and access control. Linguistic integration of these sub-languages ensures seamless integration and static checking of the aspects comprising the definition of a web application.
[More about WebDSL]
-
Modern web application development frameworks provide web application developers with high-level abstractions to improve their productivity. However, their support for static verification of applications is limited. Inconsistencies in an application are often not detected statically, but appear as errors at run-time. The reports about these errors are often obscure and hard to trace back to the source of the inconsistency. A major part of this inadequate consistency checking can be traced back to the lack of linguistic integration of these frameworks. Parts of an application are defined with separate domain-specific languages, which are not checked for consistency with the rest of the application. Examples include regular expressions, query languages and XML-based languages for definition of user interfaces. We give an overview and analysis of typical problems arising in development with frameworks for web application development, with Ruby on Rails, Lift and Seam as representatives. To remedy these problems, in this paper, we argue that domain-specific languages should be designed from the ground up with static verification and cross-aspect consistency checking in mind, providing linguistic integration of domain-specific sub-languages. We show how this approach is applied in the design of WebDSL, a domain-specific language for web applications, by examining how its compiler detects inconsistencies not caught by web frameworks, providing accurate and clear error messages. Furthermore, we show how this consistency analysis can be expressed with a declarative rule-based approach using the Stratego transformation language.
-
WebDSL is a domain-specific language for Web information systems that maintains separation of concerns while integrating its sublanguages, enabling consistency checking and reusing common language concepts.
-
In this paper, we present the extension of WebDSL, a domain-specific language for web application development, with abstractions for declarative definition of access control. The extension supports the definition of a wide range of access control policies concisely and transparently as a separate concern. In addition to regulating the access to pages and actions, access control rules are used to infer navigation options not accessible to the current user, preventing the presentation of inaccessible links. The extension is an illustration of a general approach to the design of domain-specific languages for different technical domains to support separation of concerns in application development, while preserving linguistic integration. This approach is realized by means of a transformational semantics that weaves separately defined aspects into an integrated implementation.
-
The goal of domain-specific languages (DSLs) is to increase the productivity of software engineers by abstracting from low-level boil- erplate code. Introduction of DSLs in the software development process requires a smooth workflow for the production of DSLs themselves. This requires technology for designing and implementing DSLs, but also a methodology for using that technology. That is, a collection of guidelines, design patterns, and reusable DSL components that show developers how to tackle common language design and implementation issues. This paper presents a case study in domain-specific language engineering. It reports on a pro ject in which the author designed and built WebDSL, a DSL for web applications with a rich data model, using several DSLs for DSL engineering: SDF for syntax definition and Stratego/XT for code gener- ation. The paper follows the stages in the development of the DSL. The contributions of the paper are three-fold. (1) A tutorial in the application of the specific SDF and Stratego/XT technology for building DSLs. (2) A description of an incremental DSL development process. (3) A domain- specific language for web-applications with rich data models. The paper concludes with a survey of related approaches.
Incremental Relational Programming with IceDust
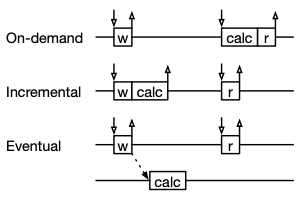 Derived values are values calculated from base values. They can be expressed with views in relational databases, or with expressions in incremental or reactive programming. However, relational views do not provide multiplicity bounds, and incremental and reactive programming require significant boilerplate code in order to encode bidirectional derived values. Moreover, the composition of various strategies for calculating derived values is either disallowed, or not checked for producing derived values which will be consistent with the derived values they depend upon. IceDust is a declarative data modeling language with derived bidirectional relations with multiplicity bounds and support for statically checked composition of calculation strategies. Derived bidirectional relations, multiplicity bounds, and calculation strategies all influence runtime behavior of changes to data, leading to hundreds of possible behavior definitions. IceDust2 uses a product-line based code generator to avoid explicitly defining all possible combinations, making it easier to reason about correctness. The type system allows only sound composition of strategies and guarantees multiplicity bounds. Finally, our case studies validate the usability of IceDust2 in applications.
[More about IceDust]
Derived values are values calculated from base values. They can be expressed with views in relational databases, or with expressions in incremental or reactive programming. However, relational views do not provide multiplicity bounds, and incremental and reactive programming require significant boilerplate code in order to encode bidirectional derived values. Moreover, the composition of various strategies for calculating derived values is either disallowed, or not checked for producing derived values which will be consistent with the derived values they depend upon. IceDust is a declarative data modeling language with derived bidirectional relations with multiplicity bounds and support for statically checked composition of calculation strategies. Derived bidirectional relations, multiplicity bounds, and calculation strategies all influence runtime behavior of changes to data, leading to hundreds of possible behavior definitions. IceDust2 uses a product-line based code generator to avoid explicitly defining all possible combinations, making it easier to reason about correctness. The type system allows only sound composition of strategies and guarantees multiplicity bounds. Finally, our case studies validate the usability of IceDust2 in applications.
[More about IceDust]
-
To provide empirical evidence to what extent migration of business logic to an incremental computing language (ICL) is useful, we report on a case study on a learning management system. Our contribution is to analyze a real-life project, how migrating business logic to an ICL affects information system validatability, performance, and development effort. We find that the migrated code has better validatability; it is straightforward to establish that a program ‘does the right thing’. Moreover, the performance is better than the previous hand-written incremental computing solution. The effort spent on modeling business logic is reduced, but integrating that logic in the application and tuning performance takes considerable effort. Thus, the ICL separates the concerns of business logic and performance, but does not reduce effort.
-
Derived values are values calculated from base values. They can be expressed with views in relational databases, or with expressions in incremental or reactive programming. However, relational views do not provide multiplicity bounds, and incremental and reactive programming require significant boilerplate code in order to encode bidirectional derived values. Moreover, the composition of various strategies for calculating derived values is either disallowed, or not checked for producing derived values which will be consistent with the derived values they depend upon. In this paper we present IceDust2, an extension of the declarative data modeling language IceDust with derived bidirectional relations with multiplicity bounds and support for statically checked composition of calculation strategies. Derived bidirectional relations, multiplicity bounds, and calculation strategies all influence runtime behavior of changes to data, leading to hundreds of possible behavior definitions. IceDust2 uses a product-line based code generator to avoid explicitly defining all possible combinations, making it easier to reason about correctness. The type system allows only sound composition of strategies and guarantees multiplicity bounds. Finally, our case studies validate the usability of IceDust2 in applications.
-
Derived values are values calculated from base values. They can be expressed in object-oriented languages by means of getters calculating the derived value, and in relational or logic databases by means of (materialized) views. However, switching to a different calculation strategy (for example caching) in object-oriented programming requires invasive code changes, and the databases limit expressiveness by disallowing recursive aggregation. In this paper, we present IceDust, a data modeling language for expressing derived attribute values without committing to a calculation strategy. IceDust provides three strategies for calculating derived values in persistent object graphs: Calculate-on-Read, Calculate-on-Write, and Calculate-Eventually. We have developed a path-based abstract interpretation that provides static dependency analysis to generate code for these strategies. Benchmarks show that different strategies perform better in different scenarios. In addition we have conducted a case study that suggests that derived value calculations of systems used in practice can be expressed in IceDust.
-
Object-oriented programming languages support concise navigation of relations represented by references. However, relations are not first-class citizens and bidirectional navigation is not supported. The relational paradigm provides first-class relations, but with bidirectional navigation through verbose queries. We present a systematic analysis of approaches to modeling and navigating relations. By unifying and generalizing the features of these approaches, we developed the design of a data modeling language that features first-class relations, n-ary relations, native multiplicities, bidirectional relations and concise navigation.
Mobile Web Programming with Mobl
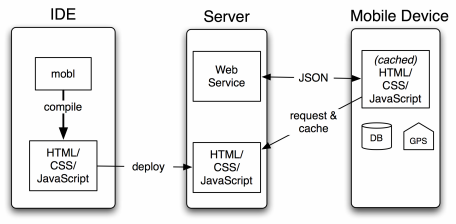 The mobl language is designed to declaratively construct mobile web applications. Mobl integrates languages for user interface design, styling, data modeling, querying and application logic into a single, unified language that is flexible, expressive, enables early detection of errors, and has good IDE support.
[More about mobl]
The mobl language is designed to declaratively construct mobile web applications. Mobl integrates languages for user interface design, styling, data modeling, querying and application logic into a single, unified language that is flexible, expressive, enables early detection of errors, and has good IDE support.
[More about mobl]
-
A new generation of mobile touch devices, such as the iPhone, iPad and Android devices, are equipped with powerful, modern browsers. However, regular websites are not optimized for the specific features and constraints of these devices, such as limited screen estate, unreliable Internet access, touch-based interaction patterns, and features such as GPS. While recent advances in web technology enable web developers to build web applications that take advantage of the unique properties of mobile devices, developing such applications exposes a number of problems, specifically: developers are required to use many loosely coupled languages with limited tool support and application code is often verbose and imperative. We introduce mobl, a new language designed to declaratively construct mobile web applications. Mobl integrates languages for user interface design, styling, data modeling, querying and application logic into a single, unified language that is flexible, expressive, enables early detection of errors, and has good IDE support.
Web Applications
Programming Education at Scale with WebLab
 How to scale programming education to large numbers of students? How to scale delivery of many assignments and exam questions for a course and still provide feedback to students? WebLab provides a web-based learning environment for programming education that supports lab assignments and proctored digital exams. WebLab is currently used in 15 courses at TU Delft, including a course on concepts of programming languages that got it all started.
[More about WebLab]
How to scale programming education to large numbers of students? How to scale delivery of many assignments and exam questions for a course and still provide feedback to students? WebLab provides a web-based learning environment for programming education that supports lab assignments and proctored digital exams. WebLab is currently used in 15 courses at TU Delft, including a course on concepts of programming languages that got it all started.
[More about WebLab]
-
A scalable infrastructure for teaching concepts of programming languages in Scala with WebLab: an experience reportIn this paper, we report on our experience in teaching a course on concepts of programming languages at TU Delft based on Krishnamurthi's PAPL book with the definitional interpreter approach using Scala as meta-language and using the WebLab learning management system. In particular, we discuss our experience with encoding of definitional interpreters in Scala using case classes, pattern matching, and recursive functions; offering this material in the web-based learning management system WebLab; automated grading and feedback of interpreter submissions using unit tests; testing tests to force students to formulate tests, instead of just implementing interpreters; generation of tests based on a reference implementation to reduce the effort of producing unit tests; and the construction of a product line of interpreters in order to maximize reuse and consistency between reference implementations.
Conference Websites with Conf.Researchr.org
 Federated conferences such as SPLASH are complex organizations composed of many parts (co-located conferences, symposia, and workshops), and are put together by many different people and committees. Developing the website for such a conference requires a considerable effort, and is often reinvented for each edition of a conference using software that provides little to no support for the domain. Conf.Researchr.Org is a domain-specific content management system developed to support the production of large conference web sites, which is being used for a growing collection of conferences, including the federated conferences of ACM SIGPLAN and ACM SIGSOFT.
[More about conf.researchr]
Federated conferences such as SPLASH are complex organizations composed of many parts (co-located conferences, symposia, and workshops), and are put together by many different people and committees. Developing the website for such a conference requires a considerable effort, and is often reinvented for each edition of a conference using software that provides little to no support for the domain. Conf.Researchr.Org is a domain-specific content management system developed to support the production of large conference web sites, which is being used for a growing collection of conferences, including the federated conferences of ACM SIGPLAN and ACM SIGSOFT.
[More about conf.researchr]
-
Conf.Researchr.Org: towards a domain-specific content management system for managing large conference websitesFederated conferences such as SPLASH are complex organizations composed of many parts (co-located conferences, symposia, and workshops), and are put together by many different people and committees. Developing the website for such a conference requires a considerable effort, and is often reinvented for each edition of a conference using software that provides little to no support for the domain. In this paper, we give a high-level overview of the design of Conf.Researchr.Org, a domain-specific content management system developed to support the production of large conference web sites, which is being used for the federated conferences of ACM SIGPLAN.
Bibliography Management with Researchr
 How to keep track of the bibliographies for your papers, share them with your co-authors, and reuse them for papers? researchr.org is a web-based bibliography management system that supports the creation of custom bibliographies. The data base is automatically updated with entries from the DBLP database. researchr is built using WebDSL
[More about researchr]
How to keep track of the bibliographies for your papers, share them with your co-authors, and reuse them for papers? researchr.org is a web-based bibliography management system that supports the creation of custom bibliographies. The data base is automatically updated with entries from the DBLP database. researchr is built using WebDSL
[More about researchr]